- Python Data Persistence - Home
- Python Data Persistence - Introduction
- Python Data Persistence - File API
- File Handling with os Module
- Python Data Persistence - Object Serialization
- Python Data Persistence - Pickle Module
- Python Data Persistence - Marshal Module
- Python Data Persistence - Shelve Module
- Python Data Persistence - dbm Package
- Python Data Persistence - CSV Module
- Python Data Persistence - JSON Module
- Python Data Persistence - XML Parsers
- Python Data Persistence - Plistlib Module
- Python Data Persistence - Sqlite3 Module
- Python Data Persistence - SQLAlchemy
- Python Data Persistence - PyMongo module
- Python Data Persistence - Cassandra Driver
- Data Persistence - ZODB
- Data Persistence - Openpyxl Module
Python Data Persistence Resources
Python Data Persistence - Cassandra Driver
Cassandra is another popular NoSQL database. High scalability, consistency, and fault-tolerance - these are some of the important features of Cassandra. This is Column store database. The data is stored across many commodity servers. As a result, data highly available.
Cassandra is a product from Apache Software foundation. Data is stored in distributed manner across multiple nodes. Each node is a single server consisting of keyspaces. Fundamental building block of Cassandra database is keyspace which can be considered analogous to a database.
Data in one node of Cassandra, is replicated in other nodes over a peer-to-peer network of nodes. That makes Cassandra a foolproof database. The network is called a data center. Multiple data centers may be interconnected to form a cluster. Nature of replication is configured by setting Replication strategy and replication factor at the time of the creation of a keyspace.
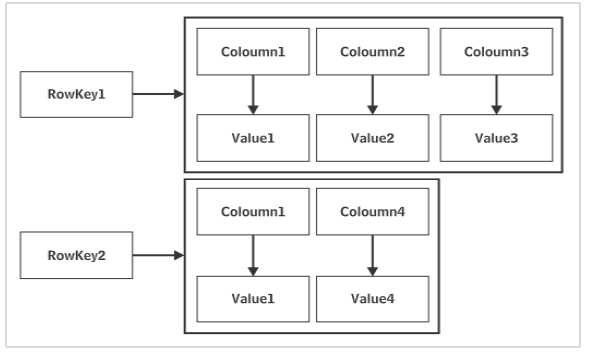
One keyspace may have more than one Column families just as one database may contain multiple tables. Cassandras keyspace doesnt have a predefined schema. It is possible that each row in a Cassandra table may have columns with different names and in variable numbers.
Cassandra software is also available in two versions: community and enterprise. The latest enterprise version of Cassandra is available for download at https://cassandra.apache.org/download/.
Cassandra has its own query language called Cassandra Query Language (CQL). CQL queries can be executed from inside a CQLASH shell similar to MySQL or SQLite shell. The CQL syntax appears similar to standard SQL.
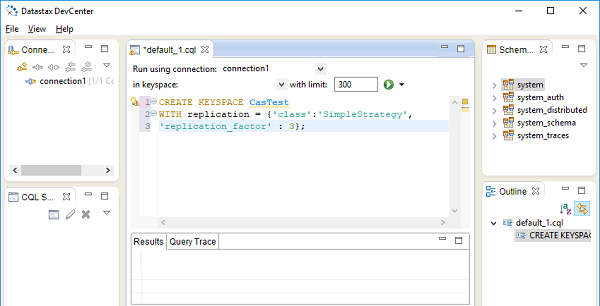
The Datastax community edition, also comes with a Develcenter IDE shown in following figure −
Python module for working with Cassandra database is called Cassandra Driver. It is also developed by Apache foundation. This module contains an ORM API, as well as a core API similar in nature to DB-API for relational databases.
Installation of Cassandra driver is easily done using pip3 utility.
pip3 install cassandra-driver
Interaction with Cassandra database, is done through Cluster object. Cassandra.cluster module defines Cluster class. We first need to declare Cluster object.
from cassandra.cluster import Cluster clstr=Cluster()
All transactions such as insert/update, etc., are performed by starting a session with a keyspace.
session=clstr.connect()
To create a new keyspace, use execute() method of session object. The execute() method takes a string argument which must be a query string. The CQL has CREATE KEYSPACE statement as follows. The complete code is as below −
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};
Here, SimpleStrategy is a value for replication strategy and replication factor is set to 3. As mentioned earlier, a keyspace contains one or more tables. Each table is characterized by it data type. Python data types are automatically parsed with corresponding CQL data types according to following table −
| Python Type | CQL Type |
|---|---|
| None | NULL |
| Bool | Boolean |
| Float | float, double |
| int, long | int, bigint, varint, smallint, tinyint, counter |
| decimal.Decimal | Decimal |
| str, Unicode | ascii, varchar, text |
| buffer, bytearray | Blob |
| Date | Date |
| Datetime | Timestamp |
| Time | Time |
| list, tuple, generator | List |
| set, frozenset | Set |
| dict, OrderedDict | Map |
| uuid.UUID | timeuuid, uuid |
To create a table, use session object to execute CQL query for creating a table.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)
The keyspace so created can be further used to insert rows. The CQL version of INSERT query is similar to SQL Insert statement. Following code inserts a row in students table.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"
As you would expect, SELECT statement is also used with Cassandra. In case of execute() method containing SELECT query string, it returns a result set object which can be traversed using a loop.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))
Cassandras SELECT query supports use of WHERE clause to apply filter on result set to be fetched. Traditional logical operators like <, > == etc. are recognized. To retrieve, only those rows from students table for names with age>20, the query string in execute() method should be as follows −
rows=session.execute("select * from students WHERE age>20 allow filtering;")
Note, the use of ALLOW FILTERING. The ALLOW FILTERING part of this statement allows to explicitly allow (some) queries that require filtering.
Cassandra driver API defines following classes of Statement type in its cassendra.query module.
SimpleStatement
A simple, unprepared CQL query contained in a query string. All examples above are examples of SimpleStatement.
BatchStatement
Multiple queries (such as INSERT, UPDATE, and DELETE) are put in a batch and executed at once. Each row is first converted as a SimpleStatement and then added in a batch.
Let us put rows to be added in Students table in the form of list of tuples as follows −
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]
To add above rows using BathStatement, run following script −
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)
PreparedStatement
Prepared statement is like a parameterized query in DB-API. Its query string is saved by Cassandra for later use. The Session.prepare() method returns a PreparedStatement instance.
For our students table, a PreparedStatement for INSERT query is as follows −
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")
Subsequently, it only needs to send the values of parameters to bind. For example −
qry=stmt.bind([1,'Ram', 23,175])
Finally, execute the bound statement above.
session.execute(qry)
This reduces network traffic and CPU utilization because Cassandra does not have to re-parse the query each time.