- Generative AI - Home
- Generative AI Basics
- Generative AI Basics
- Generative AI Evolution
- ML and Generative AI
- Generative AI Models
- Discriminative vs Generative Models
- Types of Gen AI Models
- Probability Distribution
- Probability Density Functions
- Maximum Likelihood Estimation
- Generative AI Networks
- How GANs Work?
- GAN - Architecture
- Conditional GANs
- StyleGAN and CycleGAN
- Training a GAN
- GAN Applications
- Generative AI Transformer
- Transformers in Gen AI
- Architecture of Transformers in Gen AI
- Input Embeddings in Transformers
- Multi-Head Attention
- Positional Encoding
- Feed Forward Neural Network
- Residual Connections in Transformers
- Generative AI Autoencoders
- Autoencoders in Gen AI
- Autoencoders Types and Applications
- Implement Autoencoders Using Python
- Variational Autoencoders
- Generative AI and ChatGPT
- A Generative AI Model
- Generative AI Miscellaneous
- Gen AI for Manufacturing
- Gen AI for Developers
- Gen AI for Cybersecurity
- Gen AI for Software Testing
- Gen AI for Marketing
- Gen AI for Educators
- Gen AI for Healthcare
- Gen AI for Students
- Gen AI for Industry
- Gen AI for Movies
- Gen AI for Music
- Gen AI for Cooking
- Gen AI for Media
- Gen AI for Communications
- Gen AI for Photography
Architecture of Transformers in Generative AI
Large Language Models (LLMs) based on transformers have outperformed the earlier Recurrent Neural Networks (RNNs) in various tasks like sentiment analysis, machine translation, text summarization, etc.
Transformers achieve their unique capabilities from its architecture. This chapter will explain the main ideas of the original transformer model in simple terms to make it easier to understand.
We will focus on the key components that make the transformer: the encoder, the decoder, and the unique attention mechanism that connects them both.
How do Transformers Work in Generative AI?
Lets understand how a transformer works −
- First, when we provide a sentence to the transformer, it pays extra attention to the important words in that sentence.
- It then considers all the words simultaneously rather than one after another which helps the transformer to find the dependency between the words in that sentence.
- After that, it finds the relationship between words in that sentence. For example, suppose a sentence is about stars and galaxies then it knows that these words are related.
- Once done, the transformer uses this knowledge to understand the complete story and how words connect with each other.
- With this understanding, the transformer can even predict which word might come next.
Transformer Architecture in Generative AI
The transformer has two main components: the encoder and the decoder. Below is a simplified architecture of the transformer −
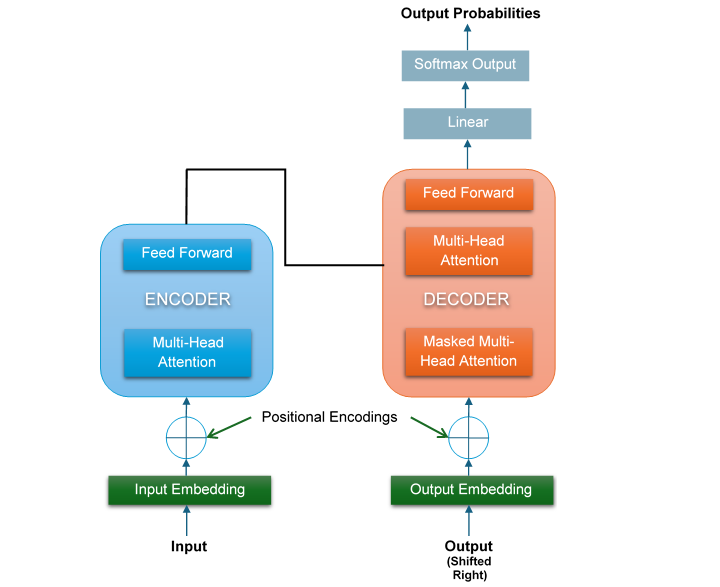
As you can see in the diagram, on the left side of the transformer, the input enters the encoder. The input is first converted to input embeddings and then crosses through an attention sub-layer and FeedForward Network (FFN) sub-layer. Similarly, on the right side, the target output enters the decoder.
The output is also first converted to output embeddings and then crosses through two attention sub-layers and a FeedForward Network (FFN) sub-layer. In this architecture, there is no RNN, LSTM, or CNN. Recurrence has also been discarded and replaced by attention mechanism.
Lets discuss the two main components, i.e., the encoder and the decoder, of the transformer in detail.
A Layer of the Encoder Stack of the Transformer
In transformer, the encoder processes the input sequences and breaks it down into some meaningful representations. The layers of the encoder of the transformer model are stacks of layers where each encoder stack layer has the following structure −
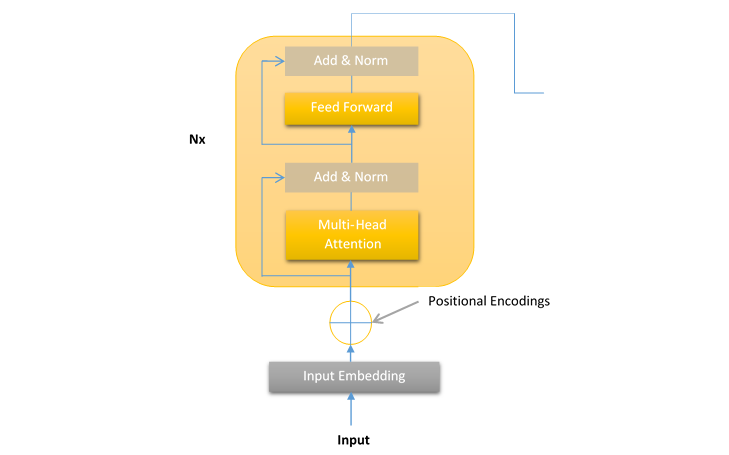
This encoder layer structure remains the same for all the layers of the Transformer model. Each layer of encoder stack contains the following two sub-layers −
- A multi-head attention mechanism
- FeedForward Network (FFN)
As we can see in the above diagram, there is a residual connection around both the sub-layers, i.e., multi-head attention mechanism and FeedForward Network. The job of these residual connections is to send the unprocessed input x of a sub-layer to a layer normalization function.
In this way, the normalized output of each layer can be calculated as below −
Layer Normalization (x + Sublayer(x))
We will discuss the sub-layers, i.e., multi-head attention and FNN, Input embeddings, positional encodings, normalization, and residual connections in detail in subsequent chapters.
A Layer of the Decoder Stack of the Transformer
In transformer, the decoder takes the representations generated by the encoder and processes them to generate output sequences. It is just like a translation or a text continuation. Like the encoder, the layers of the decoder of the transformer model are also stacks of layers where each decoder stack layer has the following structure −
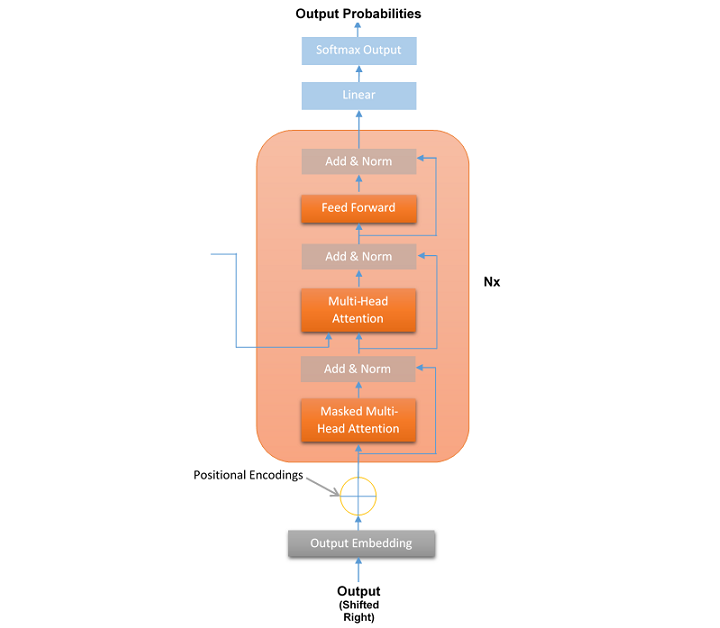
Like encoder layers, the decoder layer structure remains the same for all the N=6 layers of the Transformer model. Each layer of decoder stack contains the following three sub-layers −
- Masked multi-head attention mechanism
- A multi-head attention mechanism
- FeedForward Network (FFN)
Opposite to the encoder, the decoder has a third sub-layer called masked multi-head attention in which, at a given position, the following words are masked. The advantage of this sub-layer is that the transformer makes its predictions based on its inferences without seeing the entire sequence.
Like the encoder, there is a residual connection around all the sub-layers and the normalized output of each layer can be calculated as below −
Layer Normalization (x + Sublayer(x))
As we can see in the above diagram, after all the decoder blocks there is a final linear layer. The role of this linear layer is to map the data to the desired output vocabulary size. A softmax function is then applied to the mapped data to generate a probability distribution over the target vocabulary. This will result in the final output sequence.
Conclusion
In this chapter, we explained in detail the architecture of transformers in Generative AI. We mainly focused on its two main parts: the encoder and the decoder.
The role of the encoder is to understand the input sequence by looking at the relationships between all the words. It uses self-attention and feed-forward layers to create a detailed representation of the input.
The decoder takes the detailed representations of the input and generates the output sequence. It uses masked self-attention to ensure it generates the sequence in the correct order and utilizes encoder-decoder attention to integrate the information from the encoder.
By exploring how the encoder and the decoder work, we see how Transformers have fundamentally transformed the field of natural language processing (NLP). It is the encoder and decoder structure that make the Transformer so powerful and effective in various industries and transform the way we interact with AI systems.