- ML - Home
- ML - Introduction
- ML - Getting Started
- ML - Basic Concepts
- ML - Ecosystem
- ML - Python Libraries
- ML - Applications
- ML - Life Cycle
- ML - Required Skills
- ML - Implementation
- ML - Challenges & Common Issues
- ML - Limitations
- ML - Reallife Examples
- ML - Data Structure
- ML - Mathematics
- ML - Artificial Intelligence
- ML - Neural Networks
- ML - Deep Learning
- ML - Getting Datasets
- ML - Categorical Data
- ML - Data Loading
- ML - Data Understanding
- ML - Data Preparation
- ML - Models
- ML - Supervised Learning
- ML - Unsupervised Learning
- ML - Semi-supervised Learning
- ML - Reinforcement Learning
- ML - Supervised vs. Unsupervised
- Machine Learning Data Visualization
- ML - Data Visualization
- ML - Histograms
- ML - Density Plots
- ML - Box and Whisker Plots
- ML - Correlation Matrix Plots
- ML - Scatter Matrix Plots
- Statistics for Machine Learning
- ML - Statistics
- ML - Mean, Median, Mode
- ML - Standard Deviation
- ML - Percentiles
- ML - Data Distribution
- ML - Skewness and Kurtosis
- ML - Bias and Variance
- ML - Hypothesis
- Regression Analysis In ML
- ML - Regression Analysis
- ML - Linear Regression
- ML - Simple Linear Regression
- ML - Multiple Linear Regression
- ML - Polynomial Regression
- Classification Algorithms In ML
- ML - Classification Algorithms
- ML - Logistic Regression
- ML - K-Nearest Neighbors (KNN)
- ML - Naïve Bayes Algorithm
- ML - Decision Tree Algorithm
- ML - Support Vector Machine
- ML - Random Forest
- ML - Confusion Matrix
- ML - Stochastic Gradient Descent
- Clustering Algorithms In ML
- ML - Clustering Algorithms
- ML - Centroid-Based Clustering
- ML - K-Means Clustering
- ML - K-Medoids Clustering
- ML - Mean-Shift Clustering
- ML - Hierarchical Clustering
- ML - Density-Based Clustering
- ML - DBSCAN Clustering
- ML - OPTICS Clustering
- ML - HDBSCAN Clustering
- ML - BIRCH Clustering
- ML - Affinity Propagation
- ML - Distribution-Based Clustering
- ML - Agglomerative Clustering
- Dimensionality Reduction In ML
- ML - Dimensionality Reduction
- ML - Feature Selection
- ML - Feature Extraction
- ML - Backward Elimination
- ML - Forward Feature Construction
- ML - High Correlation Filter
- ML - Low Variance Filter
- ML - Missing Values Ratio
- ML - Principal Component Analysis
- Reinforcement Learning
- ML - Reinforcement Learning Algorithms
- ML - Exploitation & Exploration
- ML - Q-Learning
- ML - REINFORCE Algorithm
- ML - SARSA Reinforcement Learning
- ML - Actor-critic Method
- ML - Monte Carlo Methods
- ML - Temporal Difference
- Deep Reinforcement Learning
- ML - Deep Reinforcement Learning
- ML - Deep Reinforcement Learning Algorithms
- ML - Deep Q-Networks
- ML - Deep Deterministic Policy Gradient
- ML - Trust Region Methods
- Quantum Machine Learning
- ML - Quantum Machine Learning
- ML - Quantum Machine Learning with Python
- Machine Learning Miscellaneous
- ML - Performance Metrics
- ML - Automatic Workflows
- ML - Boost Model Performance
- ML - Gradient Boosting
- ML - Bootstrap Aggregation (Bagging)
- ML - Cross Validation
- ML - AUC-ROC Curve
- ML - Grid Search
- ML - Data Scaling
- ML - Train and Test
- ML - Association Rules
- ML - Apriori Algorithm
- ML - Gaussian Discriminant Analysis
- ML - Cost Function
- ML - Bayes Theorem
- ML - Precision and Recall
- ML - Adversarial
- ML - Stacking
- ML - Epoch
- ML - Perceptron
- ML - Regularization
- ML - Overfitting
- ML - P-value
- ML - Entropy
- ML - MLOps
- ML - Data Leakage
- ML - Monetizing Machine Learning
- ML - Types of Data
- Machine Learning - Resources
- ML - Quick Guide
- ML - Cheatsheet
- ML - Interview Questions
- ML - Useful Resources
- ML - Discussion
Machine Learning - Affinity Propagation
Affinity Propagation is a clustering algorithm that identifies "exemplars" in a dataset and assigns each data point to one of these exemplars. It is a type of clustering algorithm that does not require a pre-specified number of clusters, making it a useful tool for exploratory data analysis. Affinity Propagation was introduced by Frey and Dueck in 2007 and has since been widely used in many fields such as biology, computer vision, and social network analysis.
The idea behind Affinity Propagation is to iteratively update two matrices: the responsibility matrix and the availability matrix. The responsibility matrix contains information about how well-suited each data point is to serve as an exemplar for another data point, while the availability matrix contains information about how much each data point wants to select another data point as an exemplar. The algorithm alternates between updating these two matrices until convergence is achieved. The final exemplars are chosen based on the maximum values in the responsibility matrix.
Implementation in Python
In Python, the Scikit-learn library provides the AffinityPropagation class for implementing the Affinity Propagation algorithm. The class takes several parameters, including the preference parameter, which controls how many exemplars are chosen, and the damping factor, which controls the convergence speed of the algorithm.
Here is an example of how to implement Affinity Propagation using the Scikit-learn library in Python −
Example - Affinity Propagation
from sklearn.cluster import AffinityPropagation
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# generate a dataset
X, _ = make_blobs(n_samples=100, centers=4, random_state=0)
# create an instance of the AffinityPropagation class
af = AffinityPropagation(preference=-50)
# fit the model to the dataset
af.fit(X)
# print the cluster labels and the exemplars
print("Cluster labels:", af.labels_)
print("Exemplars:", af.cluster_centers_indices_)
#Plot the result
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X[:, 0], X[:, 1], c=af.labels_, cmap='viridis')
plt.scatter(af.cluster_centers_[:, 0], af.cluster_centers_[:, 1], marker='x', color='red')
plt.show()
In this example, we first generate a synthetic dataset using the make_blobs() function from Scikit-learn. We then create an instance of the AffinityPropagation class with a preference value of -50 and fit the model to the dataset using the fit() method. Finally, we print the cluster labels and the exemplars identified by the algorithm.
Output
When you execute this code, it will produce the following plot as the output −
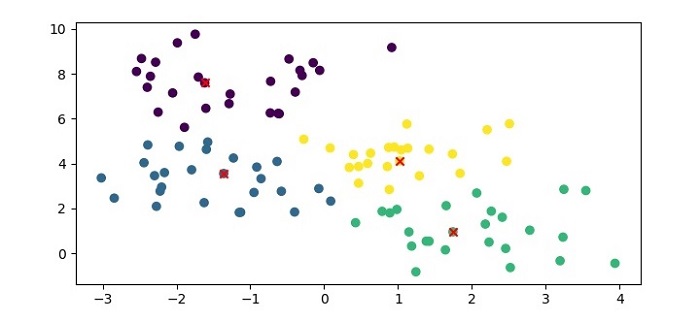
In addition, it will print the following output on the terminal −
Cluster labels: [3 0 3 3 3 3 1 0 0 0 0 0 0 0 0 2 3 3 1 2 2 0 1 2 3 1 3 3 2 2 2 0 2 2 1 3 0 2 0 1 3 1 0 1 1 0 2 1 3 1 3 2 1 1 1 0 0 2 2 0 0 2 2 3 2 0 1 1 2 3 0 2 3 0 3 3 3 1 2 2 2 0 1 1 2 1 2 2 3 3 3 1 1 1 1 0 0 1 0 1] Exemplars: [9 41 51 74]
The preference parameter in Affinity Propagation controls the number of exemplars that are chosen. A higher preference value leads to more exemplars, while a lower preference value leads to fewer exemplars. The damping factor controls the convergence speed of the algorithm, with larger damping factors leading to slower convergence.
Overall, Affinity Propagation is a powerful clustering algorithm that can identify the number of clusters automatically and does not require a pre-specified number of clusters. However, it can be computationally expensive and may not work well with very large datasets.
Advantages of Affinity Propagation
Following are the advantages of using Affinity Propagation −
Affinity Propagation can identify the number of clusters automatically without specifying the number of clusters in advance.
It can handle clusters of arbitrary shapes and sizes.
It can handle datasets with noisy or incomplete data.
It is relatively insensitive to the choice of initial parameters.
It has been shown to outperform other clustering algorithms on certain types of datasets.
Disadvantages of Affinity Propagation
Following are some of the disadvantages of using Affinity Propagation −
It can be computationally expensive for large datasets or datasets with many features.
It may converge to suboptimal solutions, especially when the data has a high degree of variability or noise.
It can be sensitive to the choice of the damping factor, which controls the rate of convergence.
It may produce many small clusters or clusters with only one or a few members, which may not be meaningful.
It can be difficult to interpret the resulting clusters, as the algorithm does not provide explicit information about the meaning or characteristics of the clusters.
