- DSA - Home
- DSA - Overview
- DSA - Environment Setup
- DSA - Algorithms Basics
- DSA - Asymptotic Analysis
- Data Structures
- DSA - Data Structure Basics
- DSA - Data Structures and Types
- DSA - Array Data Structure
- DSA - Skip List Data Structure
- Linked Lists
- DSA - Linked List Data Structure
- DSA - Doubly Linked List Data Structure
- DSA - Circular Linked List Data Structure
- Stack & Queue
- DSA - Stack Data Structure
- DSA - Expression Parsing
- DSA - Queue Data Structure
- DSA - Circular Queue Data Structure
- DSA - Priority Queue Data Structure
- DSA - Deque Data Structure
- Searching Algorithms
- DSA - Searching Algorithms
- DSA - Linear Search Algorithm
- DSA - Binary Search Algorithm
- DSA - Interpolation Search
- DSA - Jump Search Algorithm
- DSA - Exponential Search
- DSA - Fibonacci Search
- DSA - Sublist Search
- DSA - Hash Table
- Sorting Algorithms
- DSA - Sorting Algorithms
- DSA - Bubble Sort Algorithm
- DSA - Insertion Sort Algorithm
- DSA - Selection Sort Algorithm
- DSA - Merge Sort Algorithm
- DSA - Shell Sort Algorithm
- DSA - Heap Sort Algorithm
- DSA - Bucket Sort Algorithm
- DSA - Counting Sort Algorithm
- DSA - Radix Sort Algorithm
- DSA - Quick Sort Algorithm
- Matrices Data Structure
- DSA - Matrices Data Structure
- DSA - Lup Decomposition In Matrices
- DSA - Lu Decomposition In Matrices
- Graph Data Structure
- DSA - Graph Data Structure
- DSA - Depth First Traversal
- DSA - Breadth First Traversal
- DSA - Spanning Tree
- DSA - Topological Sorting
- DSA - Strongly Connected Components
- DSA - Biconnected Components
- DSA - Augmenting Path
- DSA - Network Flow Problems
- DSA - Flow Networks In Data Structures
- DSA - Edmonds Blossom Algorithm
- DSA - Maxflow Mincut Theorem
- Tree Data Structure
- DSA - Tree Data Structure
- DSA - Tree Traversal
- DSA - Binary Search Tree
- DSA - AVL Tree
- DSA - Red Black Trees
- DSA - B Trees
- DSA - B+ Trees
- DSA - Splay Trees
- DSA - Range Queries
- DSA - Segment Trees
- DSA - Fenwick Tree
- DSA - Fusion Tree
- DSA - Hashed Array Tree
- DSA - K-Ary Tree
- DSA - Kd Trees
- DSA - Priority Search Tree Data Structure
- Recursion
- DSA - Recursion Algorithms
- DSA - Tower of Hanoi Using Recursion
- DSA - Fibonacci Series Using Recursion
- Divide and Conquer
- DSA - Divide and Conquer
- DSA - Max-Min Problem
- DSA - Strassen's Matrix Multiplication
- DSA - Karatsuba Algorithm
- Greedy Algorithms
- DSA - Greedy Algorithms
- DSA - Travelling Salesman Problem (Greedy Approach)
- DSA - Prim's Minimal Spanning Tree
- DSA - Kruskal's Minimal Spanning Tree
- DSA - Dijkstra's Shortest Path Algorithm
- DSA - Map Colouring Algorithm
- DSA - Fractional Knapsack Problem
- DSA - Job Sequencing with Deadline
- DSA - Optimal Merge Pattern Algorithm
- Dynamic Programming
- DSA - Dynamic Programming
- DSA - Matrix Chain Multiplication
- DSA - Floyd Warshall Algorithm
- DSA - 0-1 Knapsack Problem
- DSA - Longest Common Sub-sequence Algorithm
- DSA - Travelling Salesman Problem (Dynamic Approach)
- Hashing
- DSA - Hashing Data Structure
- DSA - Collision In Hashing
- Disjoint Set
- DSA - Disjoint Set
- DSA - Path Compression And Union By Rank
- Heap
- DSA - Heap Data Structure
- DSA - Binary Heap
- DSA - Binomial Heap
- DSA - Fibonacci Heap
- Tries Data Structure
- DSA - Tries
- DSA - Standard Tries
- DSA - Compressed Tries
- DSA - Suffix Tries
- Treaps
- DSA - Treaps Data Structure
- Bit Mask
- DSA - Bit Mask In Data Structures
- Bloom Filter
- DSA - Bloom Filter Data Structure
- Approximation Algorithms
- DSA - Approximation Algorithms
- DSA - Vertex Cover Algorithm
- DSA - Set Cover Problem
- DSA - Travelling Salesman Problem (Approximation Approach)
- Randomized Algorithms
- DSA - Randomized Algorithms
- DSA - Randomized Quick Sort Algorithm
- DSA - Karger’s Minimum Cut Algorithm
- DSA - Fisher-Yates Shuffle Algorithm
- Miscellaneous
- DSA - Infix to Postfix
- DSA - Bellmon Ford Shortest Path
- DSA - Maximum Bipartite Matching
- DSA Useful Resources
- DSA - Questions and Answers
- DSA - Selection Sort Interview Questions
- DSA - Merge Sort Interview Questions
- DSA - Insertion Sort Interview Questions
- DSA - Heap Sort Interview Questions
- DSA - Bubble Sort Interview Questions
- DSA - Bucket Sort Interview Questions
- DSA - Radix Sort Interview Questions
- DSA - Cycle Sort Interview Questions
- DSA - Quick Guide
- DSA - Useful Resources
- DSA - Discussion
Depth First Search (DFS) Algorithm
Depth First Search (DFS) Algorithm
Depth First Search (DFS) algorithm is a recursive algorithm for searching all the vertices of a graph or tree data structure. This algorithm traverses a graph in a depthward motion and uses a stack to remember to get the next vertex to start a search, when a dead end occurs in any iteration.
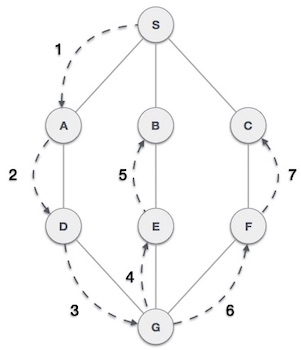
As in the example given above, DFS algorithm traverses from S to A to D to G to E to B first, then to F and lastly to C. It employs the following rules.
Rule 1 − Visit the adjacent unvisited vertex. Mark it as visited. Display it. Push it in a stack.
Rule 2 − If no adjacent vertex is found, pop up a vertex from the stack. (It will pop up all the vertices from the stack, which do not have adjacent vertices.)
Rule 3 − Repeat Rule 1 and Rule 2 until the stack is empty.
| Step | Traversal | Description |
|---|---|---|
| 1 | 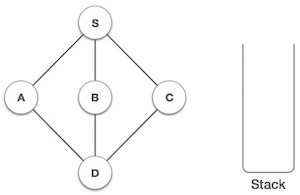 |
Initialize the stack. |
| 2 | 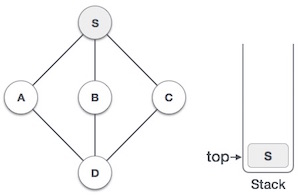 |
Mark S as visited and put it onto the stack. Explore any unvisited adjacent node from S. We have three nodes and we can pick any of them. For this example, we shall take the node in an alphabetical order. |
| 3 | 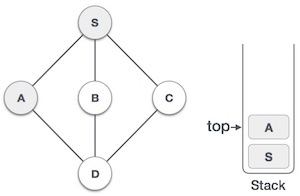 |
Mark A as visited and put it onto the stack. Explore any unvisited adjacent node from A. Both S and D are adjacent to A but we are concerned for unvisited nodes only. |
| 4 | 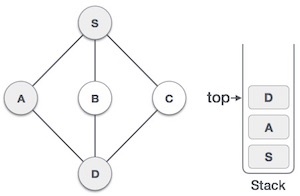 |
Visit D and mark it as visited and put onto the stack. Here, we have B and C nodes, which are adjacent to D and both are unvisited. However, we shall again choose in an alphabetical order. |
| 5 | 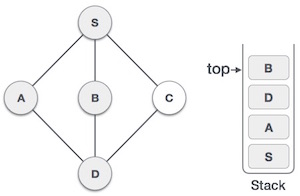 |
We choose B, mark it as visited and put onto the stack. Here B does not have any unvisited adjacent node. So, we pop B from the stack. |
| 6 | 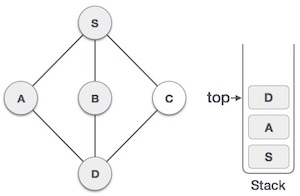 |
We check the stack top for return to the previous node and check if it has any unvisited nodes. Here, we find D to be on the top of the stack. |
| 7 | 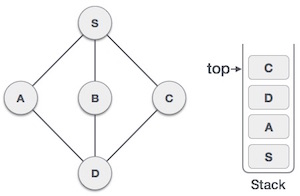 |
Only unvisited adjacent node is from D is C now. So we visit C, mark it as visited and put it onto the stack. |
As C does not have any unvisited adjacent node so we keep popping the stack until we find a node that has an unvisited adjacent node. In this case, there's none and we keep popping until the stack is empty.
Example
Following are the implementations of Depth First Search (DFS) Algorithm in various programming languages −
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 5
struct Vertex {
char label;
bool visited;
};
//stack variables
int stack[MAX];
int top = -1;
//graph variables
//array of vertices
struct Vertex* lstVertices[MAX];
//adjacency matrix
int adjMatrix[MAX][MAX];
//vertex count
int vertexCount = 0;
//stack functions
void push(int item) {
stack[++top] = item;
}
int pop() {
return stack[top--];
}
int peek() {
return stack[top];
}
bool isStackEmpty() {
return top == -1;
}
//graph functions
//add vertex to the vertex list
void addVertex(char label) {
struct Vertex* vertex = (struct Vertex*) malloc(sizeof(struct Vertex));
vertex->label = label;
vertex->visited = false;
lstVertices[vertexCount++] = vertex;
}
//add edge to edge array
void addEdge(int start,int end) {
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
//display the vertex
void displayVertex(int vertexIndex) {
printf("%c ",lstVertices[vertexIndex]->label);
}
//get the adjacent unvisited vertex
int getAdjUnvisitedVertex(int vertexIndex) {
int i;
for(i = 0; i < vertexCount; i++) {
if(adjMatrix[vertexIndex][i] == 1 && lstVertices[i]->visited == false) {
return i;
}
}
return -1;
}
void depthFirstSearch() {
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//push vertex index in stack
push(0);
while(!isStackEmpty()) {
//get the unvisited vertex of vertex which is at top of the stack
int unvisitedVertex = getAdjUnvisitedVertex(peek());
//no adjacent vertex found
if(unvisitedVertex == -1) {
pop();
} else {
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
//stack is empty, search is complete, reset the visited flag
for(i = 0;i < vertexCount;i++) {
lstVertices[i]->visited = false;
}
}
int main() {
int i, j;
for(i = 0; i < MAX; i++) { // set adjacency
for(j = 0; j < MAX; j++) // matrix to 0
adjMatrix[i][j] = 0;
}
addVertex('S'); // 0
addVertex('A'); // 1
addVertex('B'); // 2
addVertex('C'); // 3
addVertex('D'); // 4
addEdge(0, 1); // S - A
addEdge(0, 2); // S - B
addEdge(0, 3); // S - C
addEdge(1, 4); // A - D
addEdge(2, 4); // B - D
addEdge(3, 4); // C - D
printf("Depth First Search: ");
depthFirstSearch();
return 0;
}
Output
Depth First Search: S A D B C
//C++ code for Depth First Traversal
#include <iostream>
#include <array>
#include <vector>
constexpr int MAX = 5;
struct Vertex {
char label;
bool visited;
};
//stack variables
std::array<int, MAX> stack;
int top = -1;
//graph variables
//array of vertices
std::array<Vertex*, MAX> lstVertices;
//adjacency matrix
std::array<std::array<int, MAX>, MAX> adjMatrix;
//vertex count
int vertexCount = 0;
//stack functions
void push(int item) {
stack[++top] = item;
}
int pop() {
return stack[top--];
}
int peek() {
return stack[top];
}
bool isStackEmpty() {
return top == -1;
}
//graph functions
//add vertex to the vertex list
void addVertex(char label) {
Vertex* vertex = new Vertex;
vertex->label = label;
vertex->visited = false;
lstVertices[vertexCount++] = vertex;
}
//add edge to edge array
void addEdge(int start, int end) {
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
//display the vertex
void displayVertex(int vertexIndex) {
std::cout << lstVertices[vertexIndex]->label << " ";
}
//get the adjacent unvisited vertex
int getAdjUnvisitedVertex(int vertexIndex) {
for (int i = 0; i < vertexCount; i++) {
if (adjMatrix[vertexIndex][i] == 1 && !lstVertices[i]->visited) {
return i;
}
}
return -1;
}
//mark first node as visited
void depthFirstSearch() {
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//push vertex index in stack
push(0);
while (!isStackEmpty()) {
//get the unvisited vertex of vertex which is at top of the stack
int unvisitedVertex = getAdjUnvisitedVertex(peek());
//no adjacent vertex found
if (unvisitedVertex == -1) {
pop();
} else {
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
//stack is empty, search is complete, reset the visited flag
for (int i = 0; i < vertexCount; i++) {
lstVertices[i]->visited = false;
}
}
int main() {
for (int i = 0; i < MAX; i++) { //set adjacency
for (int j = 0; j < MAX; j++) { // matrix to 0
adjMatrix[i][j] = 0;
}
}
addVertex('S');
addVertex('A');
addVertex('B');
addVertex('C');
addVertex('D');
addEdge(0, 1);
addEdge(0, 2);
addEdge(0, 3);
addEdge(1, 4);
addEdge(2, 4);
addEdge(3, 4);
std::cout << "Depth First Search: ";
depthFirstSearch();
return 0;
}
Output
Depth First Search: S A D B C
//Java program for Depth First Traversal
public class DepthFirstSearch {
private static final int MAX = 5;
private static class Vertex {
char label;
boolean visited;
}
private static int[] stack = new int[MAX];
private static int top = -1;
private static Vertex[] lstVertices = new Vertex[MAX];
private static int[][] adjMatrix = new int[MAX][MAX];
private static int vertexCount = 0;
private static void push(int item) {
stack[++top] = item;
}
private static int pop() {
return stack[top--];
}
private static int peek() {
return stack[top];
}
private static boolean isStackEmpty() {
return top == -1;
}
private static void addVertex(char label) {
Vertex vertex = new Vertex();
vertex.label = label;
vertex.visited = false;
lstVertices[vertexCount++] = vertex;
}
private static void addEdge(int start, int end) {
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
private static void displayVertex(int vertexIndex) {
System.out.print(lstVertices[vertexIndex].label + " ");
}
private static int getAdjUnvisitedVertex(int vertexIndex) {
for (int i = 0; i < vertexCount; i++) {
if (adjMatrix[vertexIndex][i] == 1 && !lstVertices[i].visited) {
return i;
}
}
return -1;
}
private static void depthFirstSearch() {
lstVertices[0].visited = true;
displayVertex(0);
push(0);
while (!isStackEmpty()) {
int unvisitedVertex = getAdjUnvisitedVertex(peek());
if (unvisitedVertex == -1) {
pop();
} else {
lstVertices[unvisitedVertex].visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
for (int i = 0; i < vertexCount; i++) {
lstVertices[i].visited = false;
}
}
public static void main(String[] args) {
for (int i = 0; i < MAX; i++) {
for (int j = 0; j < MAX; j++) {
adjMatrix[i][j] = 0;
}
}
addVertex('S'); // 0
addVertex('A'); // 1
addVertex('B'); // 2
addVertex('C'); // 3
addVertex('D'); // 4
addEdge(0, 1); // S - A
addEdge(0, 2); // S - B
addEdge(0, 3); // S - C
addEdge(1, 4); // A - D
addEdge(2, 4); // B - D
addEdge(3, 4); // C - D
System.out.print("Depth First Search: ");
depthFirstSearch();
}
}
Output
Depth First Search: S A D B C
#Python program for Depth First Traversal
MAX = 5
class Vertex:
def __init__(self, label):
self.label = label
self.visited = False
#stack variables
stack = []
top = -1
#graph variables
#array of vertices
lstVertices = [None] * MAX
#adjacency matrix
adjMatrix = [[0] * MAX for _ in range(MAX)]
#vertex count
vertexCount = 0
#stack functions
def push(item):
global top
top += 1
stack.append(item)
def pop():
global top
item = stack[top]
del stack[top]
top -= 1
return item
def peek():
return stack[top]
def isStackEmpty():
return top == -1
#graph functions
#add vertex to the vertex list
def addVertex(label):
global vertexCount
vertex = Vertex(label)
lstVertices[vertexCount] = vertex
vertexCount += 1
#add edge to edge array
def addEdge(start, end):
adjMatrix[start][end] = 1
adjMatrix[end][start] = 1
#Display the Vertex
def displayVertex(vertexIndex):
print(lstVertices[vertexIndex].label, end=' ')
def getAdjUnvisitedVertex(vertexIndex):
for i in range(vertexCount):
if adjMatrix[vertexIndex][i] == 1 and not lstVertices[i].visited:
return i
return -1
def depthFirstSearch():
lstVertices[0].visited = True
displayVertex(0)
push(0)
while not isStackEmpty():
unvisitedVertex = getAdjUnvisitedVertex(peek())
if unvisitedVertex == -1:
pop()
else:
lstVertices[unvisitedVertex].visited = True
displayVertex(unvisitedVertex)
push(unvisitedVertex)
for i in range(vertexCount):
lstVertices[i].visited = False
for i in range(MAX):
for j in range(MAX):
adjMatrix[i][j] = 0
addVertex('S') # 0
addVertex('A') # 1
addVertex('B') # 2
addVertex('C') # 3
addVertex('D') # 4
addEdge(0, 1) # S - A
addEdge(0, 2) # S - B
addEdge(0, 3) # S - C
addEdge(1, 4) # A - D
addEdge(2, 4) # B - D
addEdge(3, 4) # C - D
print("Depth First Search:", end=' ')
depthFirstSearch()
Output
Depth First Search: S A D B C
Click to check C implementation of Depth First Search (BFS) Algorithm
Complexity of DFS Algorithm
Time Complexity
The time complexity of the DFS algorithm is represented in the form of O(V + E), where V is the number of nodes and E is the number of edges.
Space Complexity
The space complexity of the DFS algorithm is O(V).
