- Beautiful Soup - Home
- Beautiful Soup - Overview
- Beautiful Soup - Web Scraping
- Beautiful Soup - Installation
- Beautiful Soup - Souping the Page
- Beautiful Soup - Kinds of objects
- Beautiful Soup - Inspect Data Source
- Beautiful Soup - Scrape HTML Content
- Beautiful Soup - Navigating by Tags
- Beautiful Soup - Find Elements by ID
- Beautiful Soup - Find Elements by Class
- Beautiful Soup - Find Elements by Attribute
- Beautiful Soup - Searching the Tree
- Beautiful Soup - Modifying the Tree
- Beautiful Soup - Parsing a Section of a Document
- Beautiful Soup - Find all Children of an Element
- Beautiful Soup - Find Element using CSS Selectors
- Beautiful Soup - Find all Comments
- Beautiful Soup - Scraping List from HTML
- Beautiful Soup - Scraping Paragraphs from HTML
- BeautifulSoup - Scraping Link from HTML
- Beautiful Soup - Get all HTML Tags
- Beautiful Soup - Get Text Inside Tag
- Beautiful Soup - Find all Headings
- Beautiful Soup - Extract Title Tag
- Beautiful Soup - Extract Email IDs
- Beautiful Soup - Scrape Nested Tags
- Beautiful Soup - Parsing Tables
- Beautiful Soup - Selecting nth Child
- Beautiful Soup - Search by text inside a Tag
- Beautiful Soup - Remove HTML Tags
- Beautiful Soup - Remove all Styles
- Beautiful Soup - Remove all Scripts
- Beautiful Soup - Remove Empty Tags
- Beautiful Soup - Remove Child Elements
- Beautiful Soup - find vs find_all
- Beautiful Soup - Specifying the Parser
- Beautiful Soup - Comparing Objects
- Beautiful Soup - Copying Objects
- Beautiful Soup - Get Tag Position
- Beautiful Soup - Encoding
- Beautiful Soup - Output Formatting
- Beautiful Soup - Pretty Printing
- Beautiful Soup - NavigableString Class
- Beautiful Soup - Convert Object to String
- Beautiful Soup - Convert HTML to Text
- Beautiful Soup - Parsing XML
- Beautiful Soup - Error Handling
- Beautiful Soup - Trouble Shooting
- Beautiful Soup - Porting Old Code
Beautiful Soup - Functions Reference
- Beautiful Soup - contents Property
- Beautiful Soup - children Property
- Beautiful Soup - string Property
- Beautiful Soup - strings Property
- Beautiful Soup - stripped_strings Property
- Beautiful Soup - descendants Property
- Beautiful Soup - parent Property
- Beautiful Soup - parents Property
- Beautiful Soup - next_sibling Property
- Beautiful Soup - previous_sibling Property
- Beautiful Soup - next_siblings Property
- Beautiful Soup - previous_siblings Property
- Beautiful Soup - next_element Property
- Beautiful Soup - previous_element Property
- Beautiful Soup - next_elements Property
- Beautiful Soup - previous_elements Property
- Beautiful Soup - find Method
- Beautiful Soup - find_all Method
- Beautiful Soup - find_parents Method
- Beautiful Soup - find_parent Method
- Beautiful Soup - find_next_siblings Method
- Beautiful Soup - find_next_sibling Method
- Beautiful Soup - find_previous_siblings Method
- Beautiful Soup - find_previous_sibling Method
- Beautiful Soup - find_all_next Method
- Beautiful Soup - find_next Method
- Beautiful Soup - find_all_previous Method
- Beautiful Soup - find_previous Method
- Beautiful Soup - select Method
- Beautiful Soup - append Method
- Beautiful Soup - extend Method
- Beautiful Soup - NavigableString Method
- Beautiful Soup - new_tag Method
- Beautiful Soup - insert Method
- Beautiful Soup - insert_before Method
- Beautiful Soup - insert_after Method
- Beautiful Soup - clear Method
- Beautiful Soup - extract Method
- Beautiful Soup - decompose Method
- Beautiful Soup - replace_with Method
- Beautiful Soup - wrap Method
- Beautiful Soup - unwrap Method
- Beautiful Soup - smooth Method
- Beautiful Soup - prettify Method
- Beautiful Soup - encode Method
- Beautiful Soup - decode Method
- Beautiful Soup - get_text Method
- Beautiful Soup - diagnose Method
Beautiful Soup Useful Resources
Beautiful Soup - Quick Guide
Beautiful Soup - Overview
In today's world, we have tons of unstructured data/information (mostly web data) available freely. Sometimes the freely available data is easy to read and sometimes not. No matter how your data is available, web scraping is very useful tool to transform unstructured data into structured data that is easier to read and analyze. In other words, web scraping is a way to collect, organize and analyze this enormous amount of data. So let us first understand what is web-scraping.
Introduction to Beautiful Soup
The Beautiful Soup is a python library which is named after a Lewis Carroll poem of the same name in "Alice's Adventures in the Wonderland". Beautiful Soup is a python package and as the name suggests, parses the unwanted data and helps to organize and format the messy web data by fixing bad HTML and present to us in an easily-traversable XML structures.
In short, Beautiful Soup is a python package which allows us to pull data out of HTML and XML documents.
HTML tree Structure
Before we look into the functionality provided by Beautiful Soup, let us first understand the HTML tree structure.
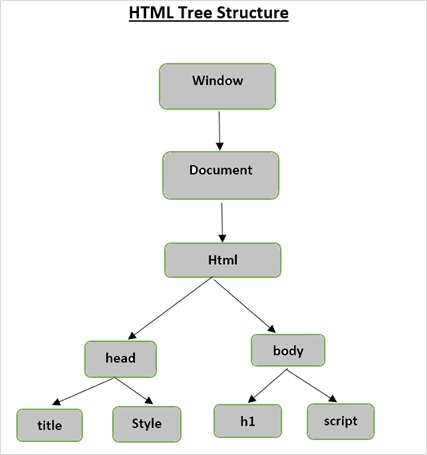
The root element in the document tree is the html, which can have parents, children and siblings and this determines by its position in the tree structure. To move among HTML elements, attributes and text, you have to move among nodes in your tree structure.
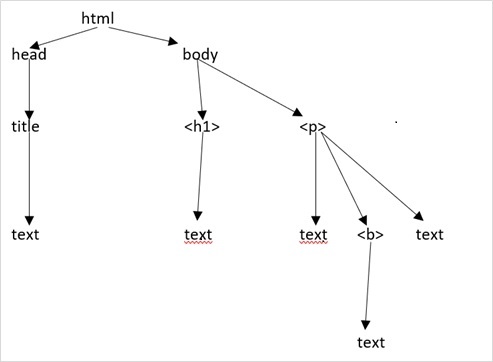
Let us suppose the webpage is as shown below −

Which translates to an html document as follows −
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
Which simply means, for above html document, we have a html tree structure as follows −
Beautiful Soup - Web Scraping
Scraping is simply a process of extracting (from various means), copying and screening of data.
When we scrape or extract data or feeds from the web (like from web-pages or websites), it is termed as web-scraping.
So, web scraping (which is also known as web data extraction or web harvesting) is the extraction of data from web. In short, web scraping provides a way to the developers to collect and analyze data from the internet.
Why Web-scraping?
Web-scraping provides one of the great tools to automate most of the things a human does while browsing. Web-scraping is used in an enterprise in a variety of ways −
Data for Research
Smart analyst (like researcher or journalist) uses web scrapper instead of manually collecting and cleaning data from the websites.
Products, prices & popularity comparison
Currently there are couple of services which use web scrappers to collect data from numerous online sites and use it to compare products popularity and prices.
SEO Monitoring
There are numerous SEO tools such as Ahrefs, Seobility, SEMrush, etc., which are used for competitive analysis and for pulling data from your client's websites.
Search engines
There are some big IT companies whose business solely depends on web scraping.
Sales and Marketing
The data gathered through web scraping can be used by marketers to analyze different niches and competitors or by the sales specialist for selling content marketing or social media promotion services.
Why Python for Web Scraping?
Python is one of the most popular languages for web scraping as it can handle most of the web crawling related tasks very easily.
Below are some of the points on why to choose python for web scraping −
Ease of Use
As most of the developers agree that python is very easy to code. We don't have to use any curly braces "{ }" or semi-colons ";" anywhere, which makes it more readable and easy-to-use while developing web scrapers.
Huge Library Support
Python provides huge set of libraries for different requirements, so it is appropriate for web scraping as well as for data visualization, machine learning, etc.
Easily Explicable Syntax
Python is a very readable programming language as python syntax are easy to understand. Python is very expressive and code indentation helps the users to differentiate different blocks or scopes in the code.
Dynamically-typed language
Python is a dynamically-typed language, which means the data assigned to a variable tells, what type of variable it is. It saves lot of time and makes work faster.
Huge Community
Python community is huge which helps you wherever you stuck while writing code.
Beautiful Soup - Installation
Beautiful Soup is a library that makes it easy to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.
BeautifulSoup package is not a part of Python's standard library, hence it must be installed. Before installing the latest version, let us create a virtual environment, as per Python's recommended method.
A virtual environment allows us to create an isolated working copy of python for a specific project without affecting the outside setup.
We shall use venv module in Python's standard library to create virtual environment. PIP is included by default in Python version 3.4 or later.
Use the following command to create virtual environment in Windows
D:\beautiful_soup>py -m venv myenv
On Ubuntu Linux, update the APT repo and install venv if required before creating virtual environment
mvl@GNVBGL3:~ $ sudo apt update && sudo apt upgrade -y mvl@GNVBGL3:~ $ sudo apt install python3-venv
Then use the following command to create a virtual environment
mvl@GNVBGL3:~ $ sudo python3 -m venv myenv
You need to activate the virtual environment. On Windows use the command
D:\beautiful_soup>cd myenv D:\beautiful_soupmyenv>scripts\activate (myenv) D:\beautiful_soup\myenv>
On Ubuntu Linux, use following command to activate the virtual environment
mvl@GNVBGL3:~$ cd myenv mvl@GNVBGL3:~/myenv$ source bin/activate (myenv) mvl@GNVBGL3:~/myenv$
Name of the virtual environment appears in the parenthesis. Now that it is activated, we can now install BeautifulSoup in it.
D:\beautiful_soup\myenv\pythonProject> pip3 install beautifulsoup4
Collecting beautifulsoup4
Obtaining dependency information for beautifulsoup4 from https://files.pythonhosted.org/packages/1a/39/47f9197bdd44df24d67ac8893641e16f386c984a0619ef2ee4c51fbbc019/beautifulsoup4-4.14.3-py3-none-any.whl.metadata
Downloading beautifulsoup4-4.14.3-py3-none-any.whl.metadata (3.8 kB)
Collecting soupsieve>=1.6.1 (from beautifulsoup4)
Obtaining dependency information for soupsieve>=1.6.1 from https://files.pythonhosted.org/packages/14/a0/bb38d3b76b8cae341dad93a2dd83ab7462e6dbcdd84d43f54ee60a8dc167/soupsieve-2.8-py3-none-any.whl.metadata
Downloading soupsieve-2.8-py3-none-any.whl.metadata (4.6 kB)
Collecting typing-extensions>=4.0.0 (from beautifulsoup4)
Obtaining dependency information for typing-extensions>=4.0.0 from https://files.pythonhosted.org/packages/18/67/36e9267722cc04a6b9f15c7f3441c2363321a3ea07da7ae0c0707beb2a9c/typing_extensions-4.15.0-py3-none-any.whl.metadata
Downloading typing_extensions-4.15.0-py3-none-any.whl.metadata (3.3 kB)
Downloading beautifulsoup4-4.14.3-py3-none-any.whl (107 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 107.7/107.7 kB 3.1 MB/s eta 0:00:00
Downloading soupsieve-2.8-py3-none-any.whl (36 kB)
Downloading typing_extensions-4.15.0-py3-none-any.whl (44 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.6/44.6 kB ? eta 0:00:00
Installing collected packages: typing-extensions, soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.14.3 soupsieve-2.8 typing-extensions-4.15.0
Note that the latest version of Beautifulsoup4 is 4.12.2 and requires Python 3.8 or later.
If you don't have easy_install or pip installed, you can download the Beautiful Soup 4 source tarball and install it with setup.py.
(myenv) mvl@GNVBGL3:~/myenv$ python setup.py install
To check if Beautifulsoup is properly install, enter following commands in Python terminal −
>>> import bs4 >>> bs4.__version__ '4.14.3'
If the installation hasn't been successful, you will get ModuleNotFoundError.
You will also need to install requests library. It is a HTTP library for Python.
pip3 install requests
Installing a Parser
By default, Beautiful Soup supports the HTML parser included in Python's standard library, however it also supports many external third party python parsers like lxml parser or html5lib parser.
To install lxml or html5lib parser, use the command:
pip3 install lxml pip3 install html5lib
These parsers have their advantages and disadvantages as shown below −
Parser: Python's html.parser
Usage − BeautifulSoup(markup, "html.parser")
Advantages
- Batteries included
- Decent speed
- Lenient (As of Python 3.2)
Disadvantages
- Not as fast as lxml, less lenient than html5lib.
Parser: lxml's HTML parser
Usage − BeautifulSoup(markup, "lxml")
Advantages
- Very fast
- Lenient
Disadvantages
- External C dependency
Parser: lxml's XML parser
Usage − BeautifulSoup(markup, "lxml-xml")
Or BeautifulSoup(markup, "xml")
Advantages
- Very fast
- The only currently supported XML parser
Disadvantages
- External C dependency
Parser: html5lib
Usage − BeautifulSoup(markup, "html5lib")
Advantages
- Extremely lenient
- Parses pages the same way a web browser does
- Creates valid HTML5
Disadvantages
- Very slow
- External Python dependency
Beautiful Soup - Souping the page
It is time to test our Beautiful Soup package in one of the html pages (taking web page - https://www.tutorialspoint.com/index.htm, you can choose any-other web page you want) and extract some information from it.
In the below code, we are trying to extract the title from the webpage −
Example - Extracting Title from a Web Page
tester.py
from bs4 import BeautifulSoup import requests url = "https://www.tutorialspoint.com/index.htm" req = requests.get(url) soup = BeautifulSoup(req.content, "html.parser") print(soup.title)
Output
Run the above code and verify the output.
<title>Online Courses and eBooks Library<title>
One common task is to extract all the URLs within a webpage. For that we just need to add the below line of code −
for link in soup.find_all('a'):
print(link.get('href'))
Output
Shown below is the partial output of the above loop −
https://www.tutorialspoint.com/index.htm https://www.tutorialspoint.com/codingground.htm https://www.tutorialspoint.com/about/about_careers.htm https://www.tutorialspoint.com/whiteboard.htm https://www.tutorialspoint.com/online_dev_tools.htm https://www.tutorialspoint.com/business/index.asp https://www.tutorialspoint.com/market/teach_with_us.jsp https://www.facebook.com/tutorialspointindia https://www.instagram.com/tutorialspoint_/ https://twitter.com/tutorialspoint https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg https://www.tutorialspoint.com/categories/development https://www.tutorialspoint.com/categories/it_and_software https://www.tutorialspoint.com/categories/data_science_and_ai_ml https://www.tutorialspoint.com/categories/cyber_security https://www.tutorialspoint.com/categories/marketing https://www.tutorialspoint.com/categories/office_productivity https://www.tutorialspoint.com/categories/business https://www.tutorialspoint.com/categories/lifestyle https://www.tutorialspoint.com/latest/prime-packs https://www.tutorialspoint.com/market/index.asp https://www.tutorialspoint.com/latest/ebooks
To parse a web page stored locally in the current working directory, obtain the file object pointing to the html file, and use it as argument to the BeautifulSoup() constructor.
Example - Parsing a Local Web Page
tester.py
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup)
Output
<html> <head> <title>Hello World</title> </head> <body> <h1 style="text-align:center;">Hello World</h1> </body> </html>
Example - Parsing a HTML Script passed as String
You can also use a string that contains HTML script as constructor's argument as follows −
tester.py
from bs4 import BeautifulSoup
html = '''
<html>
<head>
<title>Hello World</title>
</head>
<body>
<h1 style="text-align:center;">Hello World</h1>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
print(soup)
Output
<html> <head> <title>Hello World</title> </head> <body> <h1 style="text-align:center;">Hello World</h1> </body> </html>
Beautiful Soup uses the best available parser to parse the document. It will use an HTML parser unless specified otherwise.
Beautiful Soup - Kinds of objects
When we pass a html document or string to a beautifulsoup constructor, beautifulsoup basically converts a complex html page into different python objects. Below we are going to discuss four major kinds of objects defined in bs4 package.
- Tag
- NavigableString
- BeautifulSoup
- Comments
Tag Object
A HTML tag is used to define various types of content. A tag object in BeautifulSoup corresponds to an HTML or XML tag in the actual page or document.
Example - Getting type of Tag.
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
print (type(tag))
Output
<class 'bs4.element.Tag'>
Tags contain lot of attributes and methods and two important features of a tag are its name and attributes.
Name (tag.name)
Every tag contains a name and can be accessed through '.name' as suffix. tag.name will return the type of tag it is.
Example - Printing Name of the Tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
print (tag.name)
Output
html
However, if we change the tag name, same will be reflected in the HTML markup generated by the BeautifulSoup.
Example - Changing the tag name
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
tag.name = "strong"
print (tag)
Output
<strong><body><b class="boldest">TutorialsPoint</b></body></strong>
Attributes (tag.attrs)
A tag object can have any number of attributes. In the above example, the tag <b class="boldest"> has an attribute 'class' whose value is "boldest". Anything that is NOT tag, is basically an attribute and must contain a value. A dictionary of attributes and their values is returned by "attrs". You can access the attributes either through accessing the keys too.
In the example below, the string argument for Beautifulsoup() constructor contains HTML input tag. The attributes of input tag are returned by "attr".
Example - Printing attributes of a Tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
print (tag.attrs)
Output
{'type': 'text', 'name': 'name', 'value': 'Raju'}
We can do all kind of modifications to our tag's attributes (add/remove/modify), using dictionary operators or methods.
In the following example, the value tag is updated. The updated HTML string shows changes.
Example - Updating tag value
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
print (tag.attrs)
tag['value']='Ravi'
print (soup)
Output
<html><body><input name="name" type="text" value="Ravi"/></body></html>
We add a new id tag, and delete the value tag.
Example - Adding/Deleting Tag
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
tag['id']='nm'
del tag['value']
print (soup)
Output
<html><body><input id="nm" name="name" type="text"/></body></html>
Multi-valued attributes
Some of the HTML5 attributes can have multiple values. Most commonly used is the class-attribute which can have multiple CSS-values. Others include 'rel', 'rev', 'headers', 'accesskey' and 'accept-charset'. The multi-valued attributes in beautiful soup are shown as list.
Example - Using multivalued attributes
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('<p class="body"></p>', 'lxml')
print ("css_soup.p['class']:", css_soup.p['class'])
css_soup = BeautifulSoup('<p class="body bold"></p>', 'lxml')
print ("css_soup.p['class']:", css_soup.p['class'])
Output
css_soup.p['class']: ['body'] css_soup.p['class']: ['body', 'bold']
However, if any attribute contains more than one value but it is not multi-valued attributes by any-version of HTML standard, beautiful soup will leave the attribute alone −
Example - Invalid attribute values
from bs4 import BeautifulSoup
id_soup = BeautifulSoup('<p id="body bold"></p>', 'lxml')
print ("id_soup.p['id']:", id_soup.p['id'])
print ("type(id_soup.p['id']):", type(id_soup.p['id']))
Output
id_soup.p['id']: body bold type(id_soup.p['id']): <class 'str'>
NavigableString object
Usually, a certain string is placed in opening and closing tag of a certain type. The HTML engine of the browser applies the intended effect on the string while rendering the element. For example , in <b>Hello World</b>, you find a string in the middle of <b> and </b> tags so that it is rendered in bold.
The NavigableString object represents the contents of a tag. It is an object of bs4.element.NavigableString class. To access the contents, use ".string" with tag.
Example - Printing type of NavigableString
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>", 'html.parser')
print (soup.string)
print (type(soup.string))
Output
Hello, Tutorialspoint! <class 'bs4.element.NavigableString'>
A NavigableString object is similar to a Python Unicode string. some of its features support Navigating the tree and Searching the tree. A NavigableString can be converted to a Unicode string with str() function.
Example - Converting NavigableString to String
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
string = str(tag.string)
print (string)
Output
Hello, Tutorialspoint!
Just as a Python string, which is immutable, the NavigableString also can't be modified in place. However, use replace_with() to replace the inner string of a tag with another.
Example - Updating a NavigableString
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
tag.string.replace_with("OnLine Tutorials Library")
print (tag.string)
Output
OnLine Tutorials Library
BeautifulSoup object
The BeautifulSoup object represents the entire parsed object. However, it can be considered to be similar to Tag object. It is the object created when we try to scrape a web resource. Because it is similar to a Tag object, it supports the functionality required to parse and search the document tree.
Example - Usage of BeautifulSoup
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
print (soup)
print (soup.name)
print ('type:',type(soup))
Output
<html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul> <li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html> [document] type: <class 'bs4.BeautifulSoup'>
The name property of BeautifulSoup object always returns [document].
Two parsed documents can be combined if you pass a BeautifulSoup object as an argument to a certain function such as replace_with().
Example - Updating content using BeautifulSoup
from bs4 import BeautifulSoup
obj1 = BeautifulSoup("<book><title>Python</title></book>", features="xml")
obj2 = BeautifulSoup("<b>Beautiful Soup parser</b>", "lxml")
obj2.find('b').replace_with(obj1)
print (obj2)
Output
<html><body><book><title>Python</title></book></body></html>
Comment object
Any text written between <!-- and --> in HTML as well as XML document is treated as comment. BeautifulSoup can detect such commented text as a Comment object.
Example - Usage of Comment in Beautiful Soup
from bs4 import BeautifulSoup markup = "<b><!--This is a comment text in HTML--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string print (comment, type(comment))
Output
This is a comment text in HTML <class 'bs4.element.Comment'>
The Comment object is a special type of NavigableString object. The prettify() method displays the comment text with special formatting −
Example - Formatting a Comment
print (soup.b.prettify())
Output
<b> <!--This is a comment text in HTML--> </b>
Beautiful Soup - Inspect Data Source
In order to scrape a web page with BeautifulSoup and Python, your first step for any web scraping project should be to explore the website that you want to scrape. So, first visit the website to understand the site structure before you start extracting the information that's relevant for you.
Let us visit TutorialsPoint's Python Tutorial home page. Open https://www.tutorialspoint.com/python/index.htm in your browser.
Use Developer tools can help you understand the structure of a website. All modern browsers come with developer tools installed.
If using Chrome browser, open the Developer Tools from the top-right menu button (⋮) and selecting More Tools → Developer Tools.
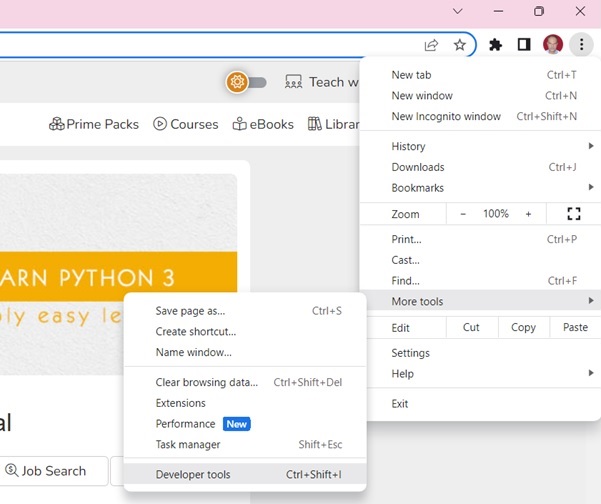
With Developer tools, you can explore the site's document object model (DOM) to better understand your source. Select the Elements tab in developer tools. You'll see a structure with clickable HTML elements.
The Tutorial page shows the table of contents in the left sidebar. Right click on any chapter and choose Inspect option.
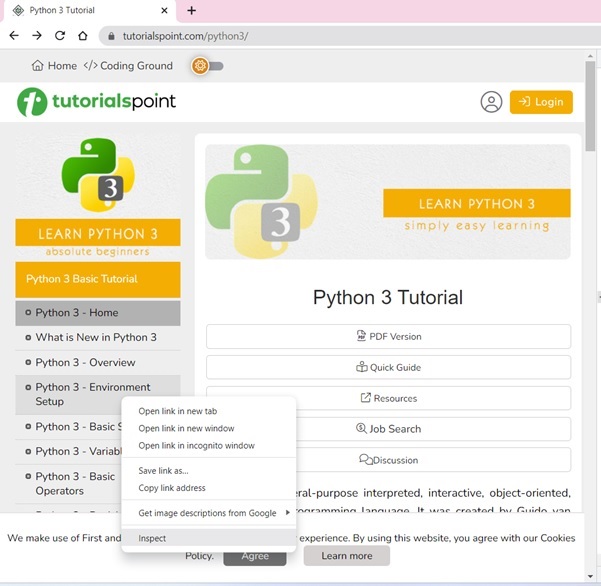
For the Elements tab, locate the tag that corresponds to the TOC list, as shown in the figure below −
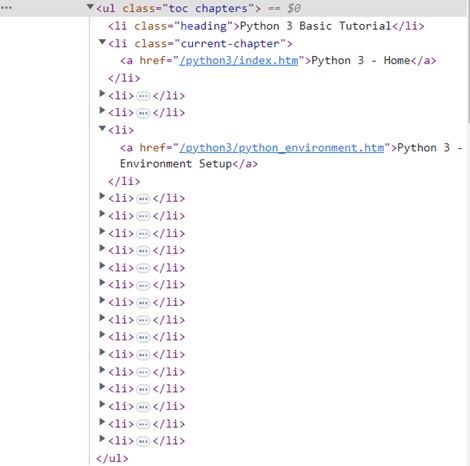
Right click on the HTML element, copy the HTML element, and paste it in any editor.
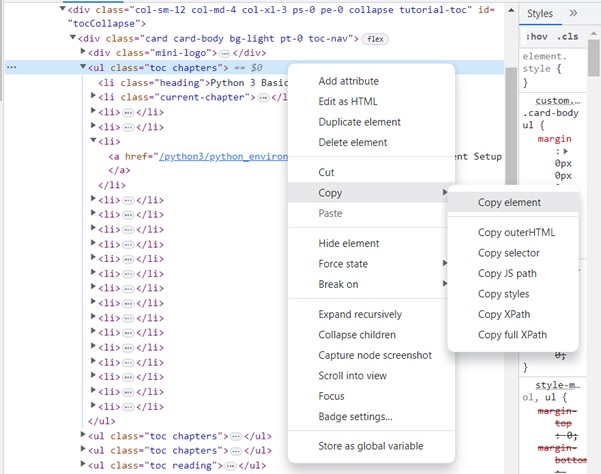
The HTML script of the <ul>..</ul> element is now obtained.
<ul class="toc chapters"> <li class="heading">Python 3 Basic Tutorial</li> <li class="current-chapter"><a href="/python3/index.htm">Python 3 - Home</a></li> <li><a href="/python3/python3_whatisnew.htm">What is New in Python 3</a></li> <li><a href="/python3/python_overview.htm">Python 3 - Overview</a></li> <li><a href="/python3/python_environment.htm">Python 3 - Environment Setup</a></li> <li><a href="/python3/python_basic_syntax.htm">Python 3 - Basic Syntax</a></li> <li><a href="/python3/python_variable_types.htm">Python 3 - Variable Types</a></li> <li><a href="/python3/python_basic_operators.htm">Python 3 - Basic Operators</a></li> <li><a href="/python3/python_decision_making.htm">Python 3 - Decision Making</a></li> <li><a href="/python3/python_loops.htm">Python 3 - Loops</a></li> <li><a href="/python3/python_numbers.htm">Python 3 - Numbers</a></li> <li><a href="/python3/python_strings.htm">Python 3 - Strings</a></li> <li><a href="/python3/python_lists.htm">Python 3 - Lists</a></li> <li><a href="/python3/python_tuples.htm">Python 3 - Tuples</a></li> <li><a href="/python3/python_dictionary.htm">Python 3 - Dictionary</a></li> <li><a href="/python3/python_date_time.htm">Python 3 - Date & Time</a></li> <li><a href="/python3/python_functions.htm">Python 3 - Functions</a></li> <li><a href="/python3/python_modules.htm">Python 3 - Modules</a></li> <li><a href="/python3/python_files_io.htm">Python 3 - Files I/O</a></li> <li><a href="/python3/python_exceptions.htm">Python 3 - Exceptions</a></li> </ul>
We can now load this script in a BeautifulSoup object to parse the document tree.
Beautiful Soup - Scrape HTML Content
The process of extracting data from websites is called Web scraping. A web page may have urls, Email addresses, images or any other content, which we can be stored in a file or database. Searching a website manually is cumbersome process. There are different web scaping tools that automate the process.
Web scraping is is sometimes prohibited by the use of 'robots.txt' file. Some popular sites provide APIs to access their data in a structured way. Unethical web scraping may result in getting your IP blocked.
Python is widely used for web scraping. Python standard library has urllib package, which can be used to extract data from HTML pages. Since urllib module is bundled with the standard library, it need not be installed.
The urllib package is an HTTP client for python programming language. The urllib.request module is usefule when we want to open and read URLs. Other module in urllib package are −
urllib.error defines the exceptions and errors raised by the urllib.request command.
urllib.parse is used for parsing URLs.
urllib.robotparser is used for parsing robots.txt files.
Use the urlopen() function in urllib module to read the content of a web page from a website.
import urllib.request
response = urllib.request.urlopen('http://python.org/')
html = response.read()
You can also use the requests library for this purpose. You need to install it before using.
pip3 install requests
In the below code, the homepage of https://www.tutorialspoint.com is scraped −
from bs4 import BeautifulSoup import requests url = "https://www.tutorialspoint.com/index.htm" req = requests.get(url)
The content obtained by either of the above two methods are then parsed with Beautiful Soup.
Beautiful Soup - Navigating By Tags
One of the important pieces of element in any piece of HTML document are tags, which may contain other tags/strings (tag's children). Beautiful Soup provides different ways to navigate and iterate over's tag's children.
Easiest way to search a parse tree is to search the tag by its name.
soup.head
The soup.head function returns the contents put inside the <head> .. </head> element of a HTML page.
Following code extracts the contents of <head> element
Example - Extracting Head
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
print(soup.head)
Output
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
soup.body
Similarly, to return the contents of body part of HTML page, use soup.body
Example - Extracting html Body
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
print (soup.body)
Output
<body> <h1>Tutorialspoint Online Library</h1> <p><b>It's all Free</b></p> </body>
You can also extract specific tag (like first <h1> tag) in the <body> tag.
Example - Extracting specific tag
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
print(soup.body.h1)
Output
<h1>Tutorialspoint Online Library</h1>
soup.p
Our HTML file contains a <p> tag. We can extract the contents of this tag
Example - Extract content of <p> tag
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
print(soup.p)
Output
<p><b>It's all Free</b></p>
Tag.contents
A Tag object may have one or more PageElements. The Tag object's contents property returns a list of all elements included in it.
Let us find the elements in <head> tag of our index.html file.
Example - Finding elements of <head> tag
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.head
print (tag.contents)
Output
['\n',
<title>TutorialsPoint</title>,
'\n',
<script>
document.write("Welcome to TutorialsPoint");
</script>,
'\n']
Tag.children
The structure of tags in a HTML script is hierarchical. The elements are nested one inside the other. For example, the top level <HTML> tag includes <HEAD> and <BODY> tags, each may have other tags in it.
The Tag object has a children property that returns a list iterator object containing the enclosed PageElements.
To demonstrate the children property, we shall use the following HTML script (index.html). In the <body> section, there are two <ul> list elements, one nested in another. In other words, the body tag has top level list elements, and each list element has another list under it.
The following Python code gives a list of all the children elements of top level <ul> tag.
Example - Getting List of chidren elements
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2>Departmentwise Employees</h2>
<ul>
<li>Accounts</li>
<ul>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul>
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.ul
print (list(tag.children))
Output
['\n', <li>Accounts</li>, '\n', <ul> <li>Anand</li> <li>Mahesh</li> </ul>, '\n', <li>HR</li>, '\n', <ul> <li>Rani</li> <li>Ankita</li> </ul>, '\n']
Since the .children property returns a list_iterator, we can use a for loop to traverse the hierarchy.
Example - Traversing a hiearchy
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2>Departmentwise Employees</h2>
<ul>
<li>Accounts</li>
<ul>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul>
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.ul
for child in tag.children:
print (child)
Output
<li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul>
Tag.find_all()
This method returns a result set of contents of all the tags matching with the argument tag provided.
The following code lists all the elements with <a> tag
Example - List all elements with <a> tag
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
<a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>
<a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
result = soup.find_all("a")
print (result)
Output
[ <a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a> ]
Beautiful Soup - Find Elements by ID
In an HTML document, usually each element is assigned a unique ID. This enables the value of an element to be extracted by a front-end code such as JavaScript function.
With BeautifulSoup, you can find the contents of a given element by its ID. There are two methods by which this can be achieved - find() as well as find_all(), and select()
Using find() method
The find() method of BeautifulSoup object searches for first element that satisfies the given criteria as an argument.
The following Python code finds the element with its id as nm
Example - Find an Element by ID
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find(id = 'nm')
print (obj)
Output
<input id="nm" name="name" type="text"/>
Using find_all() method
The find_all() method also accepts a filter argument. It returns a list of all the elements with the given id. In a certain HTML document, usually a single element with a particular id. Hence, using find() instead of find_all() is preferrable to search for a given id.
Example - Find elements by ID
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all(id = 'nm')
print (obj)
Output
[<input id="nm" name="name" type="text"/>]
Note that the find_all() method returns a list. The find_all() method also has a limit parameter. Setting limit=1 to find_all() is equivalent to find()
obj = soup.find_all(id = 'nm', limit=1)
Using select() method
The select() method in BeautifulSoup class accepts CSS selector as an argument. The # symbol is the CSS selector for id. It followed by the value of required id is passed to select() method. It works as the find_all() method.
Example - Find Element using CSS Selector
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
Output
[<input id="nm" name="name" type="text"/>]
Using select_one() method
Like the find_all() method, the select() method also returns a list. There is also a select_one() method to return the first tag of the given argument.
Example - Find Elements by CSS Selector
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select_one("#nm")
print (obj)
Output
<input id="nm" name="name" type="text"/>
Beautiful Soup - Find Elements by Class
CSS (cascaded Style sheets) is a tool for designing the appearance of HTML elements. CSS rules control the different aspects of HTML element such as size, color, alignment etc.. Applying styles is more effective than defining HTML element attributes. You can apply styling rules to each HTML element. Instead of applying style to each element individually, CSS classes are used to apply similar styling to groups of HTML elements to achieve uniform web page appearance. In BeautifulSoup, it is possible to find tags styled with CSS class. In this chapter, we shall use the following methods to search for elements for a specified CSS class −
- find_all() and find() methods
- select() and select_one() methods
Class in CSS
A class in CSS is a collection of attributes specifying the different features related to appearance, such as font type, size and color, background color, alignment etc. Name of the class is prefixed with a dot (.) while declaring it.
.class {
css declarations;
}
A CSS class may be defined inline, or in a separate css file which needs to be included in the HTML script. A typical example of a CSS class could be as follows −
.blue-text {
color: blue;
font-weight: bold;
}
You can search for HTML elements defined with a certain class style with the help of following BeautifulSoup methods.
Using find() and find_all()
To search for elements with a certain CSS class used in a tag, use attrs property of Tag object as follows −
Example - Finding elements by a CSS class using attr property
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2 class="heading">Departmentwise Employees</h2>
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all(attrs={"class": "mainmenu"})
print (obj)
Output
[<li class="mainmenu">Accounts</li>, <li class="mainmenu">HR</li>]
The result is a list of all the elements with mainmenu class
To fetch the list of elements with any of the CSS classes mentioned in in attrs property, change the find_all() statement to −
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2 class="heading">Departmentwise Employees</h2>
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all(attrs={"class": ["mainmenu", "submenu"]})
print (obj)
This results into a list of all the elements with any of CSS classes used above.
[ <li class="mainmenu">Accounts</li>, <li class="submenu">Anand</li>, <li class="submenu">Mahesh</li>, <li class="mainmenu">HR</li>, <li class="submenu">Rani</li>, <li class="submenu">Ankita</li> ]
Using select() and select_one()
You can also use select() method with the CSS selector as the argument. The (.) symbol followed by the name of the class is used as the CSS selector.
Example - Finding elements using a CSS class directly
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2 class="heading">Departmentwise Employees</h2>
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select(".heading")
print (obj)
Output
[<h2 class="heading">Departmentwise Employees</h2>]
The select_one() method returns the first element found with the given class.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2 class="heading">Departmentwise Employees</h2>
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select_one(".submenu")
print (obj)
Output
<li class="submenu">Anand</li>
Beautiful Soup - Find Elements by Attributes
Both find() and find_all() methods are meant to find one or all the tags in the document as per the arguments passed to these methods. You can pass attrs parameter to these functions. The value of attrs must be a dictionary with one or more tag attributes and their values.
Using find_all() method
The following program returns a list of all the tags having input type="text" attribute.
Example - Finding tags having input type as text
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all(attrs={"type":'text'})
print (obj)
Output
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
Using find() method
The find() method returns the first tag in the parsed document that has the given attributes.
Example - Finding first tag having name as marks
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find(attrs={"name":'marks'})
print (obj)
Output
<input id="marks" name="marks" type="text"/>
Using select() method
The select() method can be called by passing the attributes to be compared against. The attributes must be put in a list object. It returns a list of all tags that have the given attribute.
In the following code, the select() method returns all the tags with type attribute.
Example - Finding all tags with given type
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("[type]")
print (obj)
Output
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
Using select_one() method
The select_one() is method is similar, except that it returns the first tag satisfying the given filter.
Example - Finding first tag with given filter.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select_one("[name='marks']")
print(obj)
Output
<input id="marks" name="marks" type="text"/>
Beautiful Soup - Searching Tree
In this chapter, we shall discuss different methods in Beautiful Soup for navigating the HTML document tree in different directions - going up and down, sideways, and back and forth.
The name of required tag lets you navigate the parse tree. For example soup.head fetches you the <head> element −
Example - Extract a Head Tree
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
print (soup.head.prettify())
Output
<head>
<title>
TutorialsPoint
</title>
</head>
Going down
A tag may contain strings or other tags enclosed in it. The .contents property of Tag object returns a list of all the children elements belonging to it.
Example - Getting tree of a content of a Tag
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.head
print (list(tag.children))
Output
[<title>TutorialsPoint</title>]
The returned object is a list, although in this case, there is only a single child tag enclosed in head element.
Using .children property
The .children property also returns a list of all the enclosed elements in a tag. Below, all the elements in body tag are given as a list.
Example - List all enclosed elements
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.body
print (list(tag.children))
Output
['\n', <p class="title"><b>Online Tutorials Library</b></p>, '\n', <p class="story">TutorialsPoint has an excellent collection of tutorials on: <a class="lang" href="https://tutorialspoint.com/Python" id="link1">Python</a>, <a class="lang" href="https://tutorialspoint.com/Java" id="link2">Java</a> and <a class="lang" href="https://tutorialspoint.com/PHP" id="link3">PHP</a>; Enhance your Programming skills.</p>, '\n', <p class="tutorial">...</p>, '\n']
Instead of getting them as a list, you can iterate over a tag's children using the .children generator −
Example - Iterating a List
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.body
for child in tag.children:
print (child)
Output
<p class="title"><b>Online Tutorials Library</b></p> <p class="story">TutorialsPoint has an excellent collection of tutorials on: <a class="lang" href="https://tutorialspoint.com/Python" id="link1">Python</a>, <a class="lang" href="https://tutorialspoint.com/Java" id="link2">Java</a> and <a class="lang" href="https://tutorialspoint.com/PHP" id="link3">PHP</a>; Enhance your Programming skills.</p> <p class="tutorial">...</p>
Using .descendents attribute
The .contents and .children attributes only consider a tag's direct children. The .descendants attribute lets you iterate over all of a tag's children, recursively: its direct children, the children of its direct children, and so on.
The BeautifulSoup object is at the top of hierarchy of all the tags. Hence its .descendents property includes all the elements in the HTML string.
Example - Usage of descendents attributes
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
print (soup.descendants)
Output
<generator object Tag.descendants at 0x7fb9333a9970>
The .descendents attribute returns a generator, which can be iterated with a for loop. Here, we list out the descendents of the head tag.
Example - Listing descendents of head tag.
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.head
for element in tag.descendants:
print (element)
Output
<title>TutorialsPoint</title> TutorialsPoint
The head tag contains a title tag, which in turn encloses a NavigableString object TutorialsPoint. The <head> tag has only one child, but it has two descendants: the <title> tag and the <title> tag's child. But the BeautifulSoup object only has one direct child (the <html> tag), but it has many descendants.
Example - Getting Elements count
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = list(soup.descendants)
print (len(tags))
Output
27
Going Up
Just as you navigate the downstream of a document with children and descendents properties, BeautifulSoup offers .parent and .parent properties to navigate the upstream of a tag
Using .parent atttribute
every tag and every string has a parent tag that contains it. You can access an element's parent with the parent attribute. In our example, the <head> tag is the parent of the <title> tag.
Example - Using .parent attribute
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.title
print (tag.parent)
Output
<head><title>TutorialsPoint</title></head>
Since the title tag contains a string (NavigableString), the parent for the string is title tag itself.
Example - Getting Title Tag
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.title
string = tag.string
print (string.parent)
Output
<title>TutorialsPoint</title>
Using .parents property
You can iterate over all of an element's parents with .parents. This example uses .parents to travel from an <a> tag buried deep within the document, to the very top of the document. In the following code, we track the parents of the first <a> tag in the example HTML string.
Example - Usage of .parents property
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.a
print (tag.string)
for parent in tag.parents:
print (parent.name)
Output
Python p body html [document]
Sideways
The HTML tags appearing at the same indentation level are called siblings. Consider the following HTML snippet
<p>
<b>
Hello
</b>
<i>
Python
</i>
</p>
In the outer <p> tag, we have <b> and <i> tags at the same indent level, hence they are called siblings. BeautifulSoup makes it possible to navigate between the tags at same level.
.next_sibling and .previous_sibling
These attributes respectively return the next tag at the same level, and the previous tag at same level.
Example - Getting Siblings
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.next_sibling)
tag2 = soup.i
print ("previous:",tag2.previous_sibling)
Output
next: <i>Python</i> previous: <b>Hello</b>
Since the <b> tag doesn't have a sibling to its left, and <i> tag doesn't have a sibling to its right, it returns None in both cases.
Example - Checking siblings if not present
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.previous_sibling)
tag2 = soup.i
print ("previous:",tag2.next_sibling)
Output
next: None previous: None
.next_siblings and .previous_siblings
If there are two or more siblings to the right or left of a tag, they can be navigated with the help of the .next_siblings and .previous_siblings attributes respectively. Both of them return generator object so that a for loop can be used to iterate.
Let us use the following HTML snippet for this purpose −
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
Use the following code to traverse next and previous sibling tags.
Example - Traversing siblings
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.b
print ("next siblings:")
for tag in tag1.next_siblings:
print (tag)
print ("previous siblings:")
tag2 = soup.u
for tag in tag2.previous_siblings:
print (tag)
Output
next siblings: <i>Python</i> <u>Tutorial</u> previous siblings: <i>Python</i> <b>Excellent</b>
Back and forth
In Beautiful Soup, the next_element property returns the next string or tag in the parse tree. On the other hand, the previous_element property returns the previous string or tag in the parse tree. Sometimes, the return value of next_element and previous_element attributes is similar to next_sibling and previous_sibling properties.
.next_element and .previous_element
Example - Usage of .next_element and .previous_element
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("a", id="link3")
print (tag.next_element)
tag = soup.find("a", id="link1")
print (tag.previous_element)
Output
PHP TutorialsPoint has an excellent collection of tutorials on:
The next_element after <a> tag with id = "link3" is the string PHP. Similarly, the previous_element returns the string before <a> tag with id = "link1".
.next_elements and .previous_elements
These attributes of the Tag object return generator respectively of all tags and strings after and before it.
Example - Iterating Next elements
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("a", id="link1")
for element in tag.next_elements:
print (element)
Output
Python , <a class="lang" href="https://tutorialspoint.com/Java" id="link2">Java</a> Java and <a class="lang" href="https://tutorialspoint.com/PHP" id="link3">PHP</a> PHP ; Enhance your Programming skills. <p class="tutorial">...</p> ...
Example - Iterating Previous elements
from bs4 import BeautifulSoup
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("body")
for element in tag.previous_elements:
print (element)
Output
<html><head><title>TutorialsPoint</title></head>
Beautiful Soup - Modifying Tree
One of the powerful features of Beautiful Soup library is to be able to be able to manipulate the parsed HTML or XML document and modify its contents.
Beautiful Soup library has different functions to perform the following operations −
Add contents or a new tag to an existing tag of the document
Insert contents before or after an existing tag or string
Clear the contents of an already existing tag
Modify the contents of a tag element
Add content
You can add to the content of an existing tag by using append() method on a Tag object. It works like the append() method of Python's list object.
In the following example, the HTML script has a <p> tag. With append(), additional text is appended.
Example - Adding Content to P Tag
from bs4 import BeautifulSoup
markup = '<p>Hello</p>'
soup = BeautifulSoup(markup, 'html.parser')
print (soup)
tag = soup.p
tag.append(" World")
print (soup)
Output
<p>Hello</p> <p>Hello World</p>
With the append() method, you can add a new tag at the end of an existing tag. First create a new Tag object with new_tag() method and then pass it to the append() method.
Example - Appending tag
from bs4 import BeautifulSoup, Tag
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('i')
tag1.string = 'World'
tag.append(tag1)
print (soup.prettify())
Output
<b>
Hello
<i>
World
</i>
</b>
If you have to add a string to the document, you can append a NavigableString object.
Example - Appending a String
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_string = NavigableString(" World")
tag.append(new_string)
print (soup.prettify())
Output
<b> Hello World </b>
From Beautiful Soup version 4.7 onwards, the extend() method has been added to Tag class. It adds all the elements in a list to the tag.
Example - Adding multiple elements
from bs4 import BeautifulSoup markup = '<b>Hello</b>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b vals = ['World.', 'Welcome to ', 'TutorialsPoint'] tag.extend(vals) print (soup.prettify())
Output
<b> Hello World. Welcome to TutorialsPoint </b>
Insert Contents
Instead of adding a new element at the end, you can use insert() method to add an element at the given position in a the list of children of a Tag element. The insert() method in Beautiful Soup behaves similar to insert() on a Python list object.
In the following example, a new string is added to the <b> tag at position 1. The resultant parsed document shows the result.
Example - Inserting a String
from bs4 import BeautifulSoup, NavigableString markup = '<b>Excellent </b><u>from TutorialsPoint</u>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b tag.insert(1, "Tutorial ") print (soup.prettify())
Output
<b> Excellent Tutorial </b> <u> from TutorialsPoint </u>
Beautiful Soup also has insert_before() and insert_after() methods. Their respective purpose is to insert a tag or a string before or after a given Tag object. The following code shows that a string "Python Tutorial" is added after the <b> tag.
Example - Inserting After string
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_after("Python Tutorial")
print (soup.prettify())
Output
<b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
On the other hand, insert_before() method is used below, to add "Here is an " text before the <b> tag.
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("Here is an ")
print (soup.prettify())
Output
Here is an <b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
Clear the Contents
Beautiful Soup provides more than one ways to remove contents of an element from the document tree. Each of these methods has its unique features.
The clear() method is the most straight-forward. It simply removes the contents of a specified Tag element. Following example shows its usage.
Example - Removing content of a Tag
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.find('u')
tag.clear()
print (soup.prettify())
Output
<b> Excellent </b> <u> </u>
It can be seen that the clear() method removes the contents, keeping the tag intact.
Here is the Python code using clear() method
Example - Usage of clear() method
from bs4 import BeautifulSoup
html = """
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all()
for tag in tags:
tag.clear()
print (soup.prettify())
Output
<html> </html>
The extract() method removes either a tag or a string from the document tree, and returns the object that was removed.
Example
from bs4 import BeautifulSoup
html = """
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all()
for tag in tags:
obj = tag.extract()
print ("Extracted:",obj)
print (soup)
Output
Extracted: <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> Extracted: <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> Extracted: <p> The quick, brown fox jumps over a lazy dog.</p> Extracted: <p> DJs flock by when MTV ax quiz prog.</p> Extracted: <p> Junk MTV quiz graced by fox whelps.</p> Extracted: <p> Bawds jog, flick quartz, vex nymphs.</p>
You can extract either a tag or a string. The following example shows a tag being extracted.
Example - Extracting a tag
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('ol')
obj.find_next().extract()
print (soup)
Output
<ol id="HR"> <li>Ankita</li> </ol>
Change the extract() statement to remove inner text of first <li> element.
Example - Extract first element
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('ol')
obj.find_next().string.extract()
print (soup)
Output
<ol id="HR"> <li>Ankita</li> </ol>
There is another method decompose() that removes a tag from the tree, then completely destroys it and its contents −
Example - Removing a tag from tree
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag1=soup.find('ol')
tag2 = soup.find('li')
tag2.decompose()
print (soup)
print (tag2.decomposed)
Output
<ol id="HR"> <li>Ankita</li> </ol>
The decomposed property returns True or False - whether an element has been decomposed or not.
Modify the Contents
We shall look at the replace_with() method that allows contents of a tag to be replaced.
Just as a Python string, which is immutable, the NavigableString also can't be modified in place. However, use replace_with() to replace the inner string of a tag with another.
Example - Replace Tag Content
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
tag.string.replace_with("OnLine Tutorials Library")
print (tag.string)
Output
OnLine Tutorials Library
Here is another example to show the use of replace_with(). Two parsed documents can be combined if you pass a BeautifulSoup object as an argument to a certain function such as replace_with().2524
Example - Usage of replace_with() method
from bs4 import BeautifulSoup
obj1 = BeautifulSoup("<book><title>Python</title></book>", features="xml")
obj2 = BeautifulSoup("<b>Beautiful Soup parser</b>", "lxml")
obj2.find('b').replace_with(obj1)
print (obj2)
Output
<html><body><book><title>Python</title></book></body></html>
The wrap() method wraps an element in the tag you specify. It returns the new wrapper.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello Python</p>", 'html.parser')
tag = soup.p
newtag = soup.new_tag('b')
tag.string.wrap(newtag)
print (soup)
Output
<p><b>Hello Python</b></p>
On the other hand, the unwrap() method replaces a tag with whatever's inside that tag. It's good for stripping out markup.
Example - Usage of unwrap() method
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello <b>Python</b></p>", 'html.parser')
tag = soup.p
tag.b.unwrap()
print (soup)
Output
<p>Hello Python</p>
Beautiful Soup - Parsing a Section of a Document
Let's say you want to use Beautiful Soup look at a document's <a> tags only. Normally you would parse the tree and use find_all() method with the required tag as the argument.
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('a')
But that would be time consuming as well as it will take up more memory unnecessarily. Instead, you can create an object of SoupStrainer class and use it as value of parse_only argument to BeautifulSoup constructor.
A SoupStrainer tells BeautifulSoup what parts extract, and the parse tree consists of only these elements. If you narrow down your required information to a specific portion of the HTML, this will speed up your search result.
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)
Above lines of code will parse only the titles from a product site, which might be inside a tag field.
Similarly, like above we can use other soupStrainer objects, to parse specific information from an HTML tag. Below are some of the examples −
Example - Extracting details from a section.
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings = SoupStrainer(string=is_short_string)
The SoupStrainer class takes the same arguments as a typical method from Searching the tree: name, attrs, text, and **kwargs.
Note that this feature won't work if you're using the html5lib parser, because the whole document will be parsed in that case, no matter what. Hence, you should use either the inbuilt html.parser or lxml parser.
You can also pass a SoupStrainer into any of the methods covered in Searching the tree.
from bs4 import BeautifulSoup, SoupStrainer
a_tags = SoupStrainer("a")
html = """
<html>
<body>
<p> id="first" The quick, brown fox jumps over a lazy dog.</p>
<a href="www.tutorialspoint"> tutorialspoint.com </a>
<p> id="third" Junk MTV quiz graced by fox whelps.</p>
<p> id="my_unique_id" Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all(a_tags)
print(obj)
Output
[<a href="www.tutorialspoint"> tutorialspoint.com </a>]
Beautiful Soup - Find all Children of an Element
The structure of tags in a HTML script is hierarchical. The elements are nested one inside the other. For example, the top level <HTML> tag includes <HEAD> and <BODY> tags, each may have other tags in it. The top level element is called as parent. The elements nested inside the parent are its children. With the help of Beautiful Soup, we can find all the children elements of a parent element. In this chapter, we shall find out how to obtain the children of a HTML element.
There are two provisions in BeautifulSoup class to fetch the children elements.
- The .children property
- The findChildren() method
Using .children property
The .children property of a Tag object returns a generator of all the child elements in a recursive manner.
The following Python code gives a list of all the children elements of top level <ul> tag. We first obtain the Tag element corresponding to the <ul> tag, and then read its .children property
Example - Usage of .children property
from bs4 import BeautifulSoup html = """ <html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul id="dept"> <li>Accounts</li> <ul id='acc'> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html> """ soup = BeautifulSoup(html, 'html.parser') tag = soup.ul print (list(tag.children))
Output
['\n', <li>Accounts</li>, '\n', <ul> <li>Anand</li> <li>Mahesh</li> </ul>, '\n', <li>HR</li>, '\n', <ul> <li>Rani</li> <li>Ankita</li> </ul>, '\n']
Since the .children property returns a list_iterator, we can use a for loop to traverse the hierarchy.
from bs4 import BeautifulSoup html = """ <html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul id="dept"> <li>Accounts</li> <ul id='acc'> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html> """ soup = BeautifulSoup(html, 'html.parser') tag = soup.ul for child in tag.children: print (child)
Output
<li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul>
Using findChildren() method
The findChildren() method offers a more comprehensive alternative. It returns all the child elements under any top level tag.
In the index.html document, we have two nested unordered lists. The top level <ul> element has id = "dept" and the two enclosed lists are having id = "acc' and "HR' respectively.
Example - Usage of findChildren() method
In the following example, we first instantiate a Tag object pointing to top level <ul> element and extract the list of children under it.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul id="HR">
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("ul", {"id": "dept"})
children = tag.findChildren()
for child in children:
print(child)
Output
Note that the resultset includes the children under an element in a recursive fashion. Hence, in the following output, you'll find the entire inner list, followed by individual elements in it.
<li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>Anand</li> <li>Mahesh</li> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> <li>Rani</li> <li>Ankita</li>
Let us extract the children under an inner <ul> element with id='acc'. Here is the code −
Example - Extracting children
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul id="HR">
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("ul", {"id": "acc"})
children = tag.findChildren()
for child in children:
print(child)
When the above program is run, you'll obtain the <li>elements under the <ul> with id as acc.
Output
<li>Anand</li> <li>Mahesh</li>
Thus, BeautifulSoup makes it very easy to parse the children elements under any top level HTML element.
Beautiful Soup - Find Element using CSS Selectors
In Beautiful Soup library, the select() method is an important tool for scraping the HTML/XML document. Similar to find() and the other find_*() methods, the select() method also helps in locating an element that satisfies a given criteria. However, the find*() methods search for the PageElements according to the Tag name and its attributes, the select() method searches the document tree for the given CSS selector.
Beautiful Soup also has select_one() method. Difference in select() and select_one() is that, select() returns a ResultSet of all the elements belonging to the PageElement and characterized by the CSS selector; whereas select_one() returns the first occurrence of the element satisfying the CSS selector based selection criteria.
Prior to Beautiful Soup version 4.7, the select() method used to be able to support only the common CSS selectors. With version 4.7, Beautiful Soup was integrated with Soup Sieve CSS selector library. As a result, much more selectors can now be used. In the version 4.12, a .css property has been added in addition to the existing convenience methods, select() and select_one().The parameters for select() method are as follows −
select(selector, limit, **kwargs)
selector − A string containing a CSS selector.
limit − After finding this number of results, stop looking.
kwargs − Keyword arguments to be passed.
If the limit parameter is set to 1, it becomes equivalent to select_one() method. While the select() method returns a ResultSet of Tag objects, the select_one() method returns a single Tag object.
Soup Sieve Library
Soup Sieve is a CSS selector library. It has been integrated with Beautiful Soup 4, so it is installed along with Beautiful Soup package. It provides ability to select, match, and filter he document tree tags using modern CSS selectors. Soup Sieve currently implements most of the CSS selectors from the CSS level 1 specifications up to CSS level 4, except for some that are not yet implemented.
The Soup Sieve library has different types of CSS selectors. The basic CSS selectors are −
Type selector
Matching elements is done by node name. For example −
tags = soup.select('div')
Example - Usage of Type Selector
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
Output
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
Universal selector (*)
It matches elements of any type. Example −
tags = soup.select('*')
ID selector
It matches an element based on its id attribute. The symbol # denotes the ID selector. Example −
tags = soup.select("#nm")
Example - Usage of ID selector
from bs4 import BeautifulSoup
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
'''
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
Output
[<input id="nm" name="name" type="text"/>]
Class selector
It matches an element based on the values contained in the class attribute. The . symbol prefixed to the class name is the CSS class selector. Example −
tags = soup.select(".submenu")
Example - Usage of Class Selector
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
Output
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
Attribute Selectors
The attribute selector matches an element based on its attributes.
soup.select('[attr]')
Example - Usage of Attribute Selectors
from bs4 import BeautifulSoup
html = '''
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
'''
soup = BeautifulSoup(html, 'html5lib')
print(soup.select('[href]'))
Output
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>]
Pseudo Classes
CSS specification defines a number of pseudo CSS classes. A pseudo-class is a keyword added to a selector so as to define a special state of the selected elements. It adds an effect to the existing elements. For example, :link selects a link (every <a> and <area> element with an href attribute) that has not yet been visited.
The pseudo-class selectors nth-of-type and nth-child are very widely used.
:nth-of-type()
The selector :nth-of-type() matches elements of a given type, based on their position among a group of siblings. The keywords even and odd, and will respectively select elements, from a sub-group of sibling elements.
In the following example, second element of <p> type is selected.
Example - Usage of nth-of-type method
from bs4 import BeautifulSoup
html = '''
<p id="0"></p>
<p id="1"></p>
<span id="2"></span>
<span id="3"></span>
'''
soup = BeautifulSoup(html, 'html5lib')
print(soup.select('p:nth-of-type(2)'))
Output
[<p id="1"></p>]
:nth-child()
This selector matches elements based on their position in a group of siblings. The keywords even and odd will respectively select elements whose position is either even or odd amongst a group of siblings.
Usage
:nth-child(even) :nth-child(odd) :nth-child(2)
Example - Usage of nth-child method
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
child = tag.select_one(':nth-child(2)')
print (child)
Output
<p>Python</p>
Beautiful Soup - Find All Comments
Inserting comments in a computer code is supposed to be a good programming practice. Comments are helpful for understanding the logic of the program. They also serve as a documentation. You can put comments in a HTML as well as XML script, just as in a program written in C, Java, Python etc. BeautifulSoup API can be helpful to identify all the comments in a HTML document.
In HTML and XML, the comment text is written between <!-- and --> tags.
<!-- Comment Text -->
The BeutifulSoup package, whose internal name is bs4, defines Comment as an important object. The Comment object is a special type of NavigableString object. Hence, the string property of any Tag that is found between <!-- and --> is recognized as a Comment.
Example - Extracting comments
from bs4 import BeautifulSoup markup = "<b><!--This is a comment text in HTML--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string print (comment, type(comment))
Output
This is a comment text in HTML <class 'bs4.element.Comment'>
To search for all the occurrences of comment in a HTML document, we shall use find_all() method. Without any argument, find_all() returns all the elements in the parsed HTML document. You can pass a keyword argument 'string' to find_all() method. We shall assign the return value of a function iscomment() to it.
comments = soup.find_all(string=iscomment)
The iscomment() function verifies if the text in a tag is a comment object or not, with the help of isinstance() function.
def iscomment(elem): return isinstance(elem, Comment)
The comments variable shall store all the comment text occurrences in an HTML content.
The following Python program scrapes the HTML content, and finds all the comments in it.
Example - Getting all comments
from bs4 import BeautifulSoup, Comment
html = """
<html>
<head>
<!-- Title of document -->
<title>TutorialsPoint</title>
</head>
<body>
<!-- Page heading -->
<h2>Departmentwise Employees</h2>
<!-- top level list-->
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<!-- first inner list -->
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul id="HR">
<!-- second inner list -->
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
def iscomment(elem):
return isinstance(elem, Comment)
comments = soup.find_all(string=iscomment)
print (comments)
Output
[' Title of document ', ' Page heading ', ' top level list', ' first inner list ', ' second inner list ']
The above output shows a list of all comments. We can also use a for loop over the collection of comments.
Example - Looping over Collection of Comments
from bs4 import BeautifulSoup, Comment
html = """
<html>
<head>
<!-- Title of document -->
<title>TutorialsPoint</title>
</head>
<body>
<!-- Page heading -->
<h2>Departmentwise Employees</h2>
<!-- top level list-->
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<!-- first inner list -->
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul id="HR">
<!-- second inner list -->
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
def iscomment(elem):
return isinstance(elem, Comment)
comments = soup.find_all(string=iscomment)
i=0
for comment in comments:
i+=1
print (i,".",comment)
Output
1 . Title of document 2 . Page heading 3 . top level list 4 . first inner list 5 . second inner list
In this chapter, we learned how to extract all the comment strings in a HTML document.
Beautiful Soup - Scraping List from HTML
Web pages usually contain important data in the formation in the form of ordered or unordered lists. With Beautiful Soup, we can easily extract the HTML list elements, bring the data in Python objects to store in databases for further analysis. In this chapter, we shall use find() and select() methods to scrape the list data from a HTML document.
Easiest way to search a parse tree is to search the tag by its name. soup.<tag> fetches the contents of the given tag.
HTML provides <ol> and <ul> tags to compose ordered and unordered lists. Like any other tag, we can fetch the contents of these tags.
Scraping lists by Tag
In the above HTML document, we have a top-level <ul> list, inside which there's another <ul> tag and another <ol> tag. We first parse the document in soup object and retrieve contents of first <ul> in soup.ul Tag object.
Example - Scraping Lists by Tag
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
lst=soup.ul
print (lst)
Output
<ul id="dept"> <li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol> </ul>
Change value of lst to point to <ol> element to get the inner list.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
lst=soup.ol
print (lst)
Output
<ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol>
Using select() method
The select() method is essentially used to obtain data using CSS selector. However, you can also pass a tag to it. Here, we can pass the ol tag to select() method. The select_one() method is also available. It fetches the first occurrence of the given tag.
Example - Usage of select() method
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
lst=soup.select("ol")
print (lst)
Output
[<ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol>]
Using find_all() method
The find() and fin_all() methods are more comprehensive. You can pass various types of filters such as tag, attributes or string etc. to these methods. In this case, we want to fetch the contents of a list tag.
In the following code, find_all() method returns a list of all elements in the <ul> tag.
Example - Usage of find_all() method
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all("ul")
print (lst)
Output
[<ul id="dept"> <li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol> </ul>, <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul>]
We can refine the search filter by including the attrs argument. In our HTML document, the <ul> and <ol> tags, we have specified their respective id attributes. So, let us fetch the contents of <ul> element having id="acc".
Example - Filtering Lists
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all("ul", {"id":"acc"})
print (lst)
Output
[<ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul>]
Here's another example. We collect all elements with <li> tag with the inner text starting with 'A'. The find_all() method takes a keyword argument string. It takes the value of the text if the startingwith() function returns True.
Example - Usage of find_all() method with a filter
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
def startingwith(ch):
return ch.startswith('A')
lst=soup.find_all('li',string=startingwith)
print (lst)
Output
[<li>Accounts</li>, <li>Anand</li>, <li>Ankita</li>]
Beautiful Soup - Scraping Paragraphs from HTML
One of the frequently appearing tags in a HTML document is the <p> tag that marks a paragraph text. With Beautiful Soup, you can easily extract paragraph from the parsed document tree. In this chapter, we shall discuss the following ways of scraping paragraphs with the help of BeautifulSoup library.
Scraping HTML paragraph with <p> tag
Scraping HTML paragraph with find_all() method
Scraping HTML paragraph with select() method
Scraping by <p> tag
Easiest way to search a parse tree is to search the tag by its name. Hence, the expression soup.p points towards the first <p> tag in the scouped document.
para = soup.p
To fetch all the subsequent <p> tags, you can run a loop till the soup object is exhausted of all the <p> tags. The following program displays the prettified output of all the paragraph tags.
Example - Extracting all paragraphs
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
para = soup.p
print (para.prettify())
while True:
p = para.find_next('p')
if p is None:
break
print (p.prettify())
para=p
Output
<p> The quick, brown fox jumps over a lazy dog. </p> <p> DJs flock by when MTV ax quiz prog. </p> <p> Junk MTV quiz graced by fox whelps. </p> <p> Bawds jog, flick quartz, vex nymphs. </p>
Using find_all() method
The find_all() methods is more comprehensive. You can pass various types of filters such as tag, attributes or string etc. to this method. In this case, we want to fetch the contents of a <p> tag.
In the following code, find_all() method returns a list of all elements in the <p> tag.
Example - Usage of find_all() method
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
paras = soup.find_all('p')
for para in paras:
print (para.prettify())
Output
<p> The quick, brown fox jumps over a lazy dog. </p> <p> DJs flock by when MTV ax quiz prog. </p> <p> Junk MTV quiz graced by fox whelps. </p> <p> Bawds jog, flick quartz, vex nymphs. </p>
We can use another approach to find all <p> tags. To begin with, obtain list of all tags using find_all() and check Tag.name of each equals ='p'.
Example - Usage of find_all() method
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all()
paras = [tag.contents for tag in tags if tag.name=='p']
print (paras)
Output
[['The quick, brown fox jumps over a lazy dog.'], ['DJs flock by when MTV ax quiz prog.'], ['Junk MTV quiz graced by fox whelps.'], ['Bawds jog, flick quartz, vex nymphs.']]
The find_all() method also has attrs parameter. It is useful when you want to extract the <p> tag with specific attributes. For example, in the given document, the first <p> element has id='para1'. To fetch it, we need to modify the tag object as −
Example - Usage of find_all() method with filter
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
paras = soup.find_all('p', attrs={'id':'para1'})
print(paras)
Output
[The quick, brown fox jumps over a lazy dog.
]
Using select() method
The select() method is essentially used to obtain data using CSS selector. However, you can also pass a tag to it. Here, we can pass the <p> tag to select() method. The select_one() method is also available. It fetches the first occurrence of the <p> tag.
Example - Usage of select() method
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
paras = soup.select('p')
print (paras)
Output
[ <p>The quick, brown fox jumps over a lazy dog.</p>, <p>DJs flock by when MTV ax quiz prog.</p>, <p>Junk MTV quiz graced by fox whelps.</p>, <p>Bawds jog, flick quartz, vex nymphs.</p> ]
To filter out <p> tags with a certain id, use a for loop as follows −
Example - Filtering out P tag with id
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.select('p')
for tag in tags:
if tag.has_attr('id') and tag['id']=='para1':
print (tag.contents)
Output
['The quick, brown fox jumps over a lazy dog.']
Beautiful Soup - Scraping Links from HTML
While scraping and analysing the content from resources with a website, you are often required to extract all the links that a certain page contains. In this chapter, we shall find out how we can extract links from a HTML document.
HTML has the anchor tag <a> to insert a hyperlink. The href attribute of anchor tag lets you to establish the link. It uses the following syntax −
<a href=="web page URL">hypertext</a>
With the find_all() method we can collect all the anchor tags in a document and then print the value of href attribute of each of them.
In the example below, we extract all the links found on Google's home page. We use requests library to collect the HTML contents of https://google.com, parse it in a soup object, and then collect all <a> tags. Finally, we print href attributes.
Example - Extracting Links from a Web Page
from bs4 import BeautifulSoup
import requests
url = "https://www.google.com/"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
tags = soup.find_all('a')
links = [tag['href'] for tag in tags]
for link in links:
print (link)
Here's the partial output when the above program is run −
Output
https://www.google.co.in/imghp?hl=en&tab=wi https://maps.google.co.in/maps?hl=en&tab=wl https://play.google.com/?hl=en&tab=w8 https://www.youtube.com/?tab=w1 https://news.google.com/?tab=wn https://mail.google.com/mail/?tab=wm https://drive.google.com/?tab=wo https://www.google.co.in/intl/en/about/products?tab=wh http://www.google.co.in/history/optout?hl=en /preferences?hl=en https://accounts.google.com/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/&ec=GAZAAQ /advanced_search?hl=en-IN&authuser=0 https://www.google.com/url?q=https://io.google/2023/%3Futm_source%3Dgoogle-hpp%26utm_medium%3Dembedded_marketing%26utm_campaign%3Dhpp_watch_live%26utm_content%3D&source=hpp&id=19035434&ct=3&usg=AOvVaw0qzqTkP5AEv87NM-MUDd_u&sa=X&ved=0ahUKEwiPzpjku-z-AhU1qJUCHVmqDJoQ8IcBCAU
However, a HTML document may have hyperlinks of different protocol schemes, such as mailto: protocol for link to an email ID, tel: scheme for link to a telephone number, or a link to a local file with file:// URL scheme. In such a case, if we are interested in extracting links with https:// scheme, we can do so by the following example. We have a HTML document that consists of hyperlinks of different types, out of which only ones with https:// prefix are being extracted.
html = '''
<p><a href="https://www.tutorialspoint.com">Web page link </a></p>
<p><a href="https://www.example.com">Web page link </a></p>
<p><a href="mailto:nowhere@mozilla.org">Email link</a></p>
<p><a href="tel:+4733378901">Telephone link</a></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all('a')
links = [tag['href'] for tag in tags]
for link in links:
if link.startswith("https"):
print (link)
Output
https://www.tutorialspoint.com https://www.example.com
Beautiful Soup - Getting All HTML Tags
Tags in HTML are like keywords in a traditional programming language like Python or Java. Tags have a predefined behaviour according to which the its content is rendered by the browser. With Beautiful Soup, it is possible to collect all the tags in a given HTML document.
The simplest way to obtain a list of tags is to parse the web page into a soup object, and call find_all() methods without any argument. It returns a list generator, giving us a list of all the tags.
Let us extract the list of all tags in Google's homepage.
Example - Extracting all tags from a web page
from bs4 import BeautifulSoup import requests url = "https://www.google.com/" req = requests.get(url) soup = BeautifulSoup(req.content, "html.parser") tags = soup.find_all() print ([tag.name for tag in tags])
Output
['html', 'head', 'meta', 'meta', 'title', 'script', 'style', 'style', 'script', 'body', 'script', 'div', 'div', 'nobr', 'b', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'u', 'div', 'nobr', 'span', 'span', 'span', 'a', 'a', 'a', 'div', 'div', 'center', 'br', 'div', 'img', 'br', 'br', 'form', 'table', 'tr', 'td', 'td', 'input', 'input', 'input', 'input', 'input', 'div', 'input', 'br', 'span', 'span', 'input', 'span', 'span', 'input', 'script', 'input', 'td', 'a', 'input', 'script', 'div', 'div', 'br', 'div', 'style', 'div', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'span', 'div', 'div', 'a', 'a', 'a', 'a', 'p', 'a', 'a', 'script', 'script', 'script']
Naturally, you may get such a list where one certain tag may appear more than once. To obtain a list of unique tags (avoiding the duplication), construct a set from the list of tag objects.
Change the print statement in above code to fetch unique tag name
Example - Extracting unique tags from a webpage
from bs4 import BeautifulSoup
import requests
url = "https://www.google.com/"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
tags = soup.find_all()
print ({tag.name for tag in tags})
Output
{'body', 'head', 'p', 'a', 'meta', 'tr', 'nobr', 'script', 'br', 'img', 'b', 'form', 'center', 'span', 'div', 'input', 'u', 'title', 'style', 'td', 'table', 'html'}
To obtain tags with some text associated with them, check the string property and print if it is not None
from bs4 import BeautifulSoup
import requests
url = "https://www.google.com/"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
tags = soup.find_all()
for tag in tags:
if tag.string is not None:
print (tag.name, tag.string)
Output
title Google script (...
There may be some singleton tags without text but with one or more attributes as in the <img> tag. Following loop constructs lists out such tags.
In the following code, the HTML string is not a complete HTML document in the sense that thr <html> and <body> tags are not given. But the html5lib and lxml parsers add these tags on their own while parsing the document tree. Hence, when we extract the tag list, the additional tags will also be seen.
Example
html = '''
<h1 style="color:blue;text-align:center;">This is a heading</h1>
<p style="color:red;">This is a paragraph.</p>
<p>This is another paragraph</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
tags = soup.find_all()
print ({tag.name for tag in tags} )
Output
{'head', 'html', 'p', 'h1', 'body'}
Beautiful Soup - Get Text Inside Tag
There are two types of tags in HTML. Many of the tags are in pairs of opening and closing counterparts. The top level <html> tag having a corresponding closing </html> tag is the main example. Others are <body> and </body>, <p> and </p>, <h1> and </h1> and many more. Other tags are self-closing tags - such as <img> and<a>. The self-closing tags don't have a text as most of the tags with opening and closing symbols (such as <b>Hello</b>). In this chapter, we shall have a look at how can we get the text part inside such tags, with the help of Beautiful Soup library.
There are more than one methods/properties available in Beautiful Soup, with which we can fetch the text associated with a tag object.
| Sr.No | Methods & Description |
|---|---|
| 1 |
text property Get all child strings of a PageElement, concatenated using a separator if specified. |
| 2 |
string property Convenience property to string from a child element. |
| 3 |
strings property yields string parts from all the child objects under the current PageElement. |
| 4 |
stripped_strings property Same as strings property, with the linebreaks and whitespaces removed. |
| 5 |
get_text() method returns all child strings of this PageElement, concatenated using a separator if specified. |
Consider the following HTML document −
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
If we retrieve the stripped_string property of each tag in the parsed document tree, we will find that the two div tags and the p tag have two NavigableString objects, Hello and World. The <b> tag embeds world string, while <img> doesn't have a text part.
The following example fetches the text from each of the tags in the given HTML document −
Example - Usage of stripped_string property
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.find_all():
print ("Tag: {} attributes: {} ".format(tag.name, tag.attrs))
for txt in tag.stripped_strings:
print (txt)
print()
Output
Tag: div attributes: {'id': 'outer'}
Hello
World
Tag: div attributes: {'id': 'inner'}
Hello
World
Tag: p attributes: {}
Hello
World
Tag: b attributes: {}
World
Tag: img attributes: {'src': 'logo.jpg'}
Beautiful Soup - Find All Headings
In this chapter, we shall explore how to find all heading elements in a HTML document with BeautifulSoup. HTML defines six heading styles from H1 to H6, each with decreasing font size. Suitable tags are used for different page sections, such as main heading, heading for section, topic etc. Let us use the find_all() method in two different ways to extract all the heading elements in a HTML document.
Example - Filtering out headings from all tags
In this approach, we collect all the tags in the parsed tree, and check if the name of each tag is found in a list of all heading tags.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Headings</title>
</head>
<body>
<h2>Scraping Headings</h2>
<b>The quick, brown fox jumps over a lazy dog.</b>
<h3>Paragraph Heading</h3>
<p>DJs flock by when MTV ax quiz prog.</p>
<h3>List heading</h3>
<ul>
<li>Junk MTV quiz graced by fox whelps.</li>
<li>Bawds jog, flick quartz, vex nymphs.</li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
headings = ['h1','h2','h3', 'h4', 'h5', 'h6']
tags = soup.find_all()
heads = [(tag.name, tag.contents[0]) for tag in tags if tag.name in headings]
print (heads)
Here, headings is a list of all heading styles h1 to h6. If the name of a tag is any of these, the tag and its contents are collected in a lists named heads.
Output
[('h2', 'Scraping Headings'), ('h3', 'Paragraph Heading'), ('h3', 'List heading')]
Example - Getting Headings using Regex
You can pass a regex expression to the find_all() method. Take a look at the following regex.
re.compile('^h[1-6]$')
This regex finds all tags that start with h, have a digit after the h, and then end after the digit. Let use this as an argument to find_all() method in the code below −
from bs4 import BeautifulSoup
import re
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Headings</title>
</head>
<body>
<h2>Scraping Headings</h2>
<b>The quick, brown fox jumps over a lazy dog.</b>
<h3>Paragraph Heading</h3>
<p>DJs flock by when MTV ax quiz prog.</p>
<h3>List heading</h3>
<ul>
<li>Junk MTV quiz graced by fox whelps.</li>
<li>Bawds jog, flick quartz, vex nymphs.</li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all(re.compile('^h[1-6]$'))
print (tags)
Output
[<h2>Scraping Headings</h2>, <h3>Paragraph Heading</h3>, <h3>List heading</h3>]
Beautiful Soup - Extract Title Tag
The <title> tag is used to provide a text caption to the page that appears in the browser's title bar. It is not a part of the main content of the web page. The title tag is always present inside the <head> tag.
We can extract the contents of title tag by Beautiful Soup. We parse the HTML tree and obtain the title tag object.
Example - Extracting Title Tag
html = '''
<html>
<head>
<Title>Python Libraries</title>
</head>
<body>
<p Hello World</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
title = soup.title
print (title)
Output
<title>Python Libraries</title>
In HTML, we can use title attribute with all tags. The title attribute gives additional information about an element. The information is works as a tooltip text when the mouse hovers over the element.
We can extract the text of title attribute of each tag with following code snippet −
Example - Extracting Title as attribute
html = '''
<html>
<body>
<p title='parsing HTML and XML'>Beautiful Soup</p>
<p title='HTTP library'>requests</p>
<p title='URL handling'>urllib</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
tags = soup.find_all()
for tag in tags:
if tag.has_attr('title'):
print (tag.attrs['title'])
Output
parsing HTML and XML HTTP library URL handling
Beautiful Soup - Extract Email IDs
To Extract Email addresses from a web page is an important application a web scraping library such as BeautifulSoup. In any web page, the Email IDs usually appear in the href attribute of anchor <a> tag. The Email ID is written using mailto URL scheme. Many a times, the Email Address may be present in page content as a normal text (without any hyperlink). In this chapter, we shall use BeautifulSoup library to fetch Email IDs from HTML page, with simple techniques.
A typical usage of Email ID in href attribute is as below −
<a href = "mailto:xyz@abc.com">test link</a>
Example - Checking href for mailTo
Here's the Python code that finds the Email Ids. We collect all the <a> tags in the document, and check if the tag has href attribute. If true, the part of its value after 6th character is the email Id.
from bs4 import BeautifulSoup
import re
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Email IDs</title>
</head>
<body>
<h2>Contact Us</h2>
<ul>
<li><a href = "mailto:sales@company.com">Sales Enquiries</a></li>
<li><a href = "mailto:careers@company.com">Careers</a></li>
<li><a href = "mailto:partner@company.com">Partner with us</a></li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all("a")
for tag in tags:
if tag.has_attr("href") and tag['href'][:7]=='mailto:':
print (tag['href'][7:])
Output
For the given HTML content, the Email IDs will be extracted as follows −
sales@company.com careers@company.com partner@company.com
In the second example, we assume that the Email IDs appear anywhere in the text. To extract them, we use the regex searching mechanism. Regex is a complex character pattern. Python's re module helps in processing the regex (Regular Expression) patterns. The following regex pattern is used for searching the email address −
pat = r'[\w.+-]+@[\w-]+\.[\w.-]+'
Using the email regex, we'll find the appearance of the pattern in each <li> tag string. Here is the Python code −
Example - Usage of email regex
from bs4 import BeautifulSoup
import re
html = """
<html>
<head>
<title>BeautifulSoup - Scraping Email IDs</title>
</head>
<body>
<h2>Contact Us</h2>
<ul>
<li>Sales Enquiries: sales@company.com</a></li>
<li>Careers: careers@company.com</a></li>
<li>Partner with us: partner@company.com</a></li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
def isemail(s):
pat = r'[\w.+-]+@[\w-]+\.[\w.-]+'
grp=re.findall(pat,s)
return (grp)
tags = soup.find_all('li')
for tag in tags:
emails = isemail(tag.string)
if emails:
print (emails)
Output
['sales@company.com'] ['careers@company.com'] ['partner@company.com']
Using the simple techniques described above, we can use BeautifulSoup to extract Email IDs from web pages.
Beautiful Soup - Scrape Nested Tags
The arrangement of tags or elements in a HTML document is hierarchical nature. The tags are nested upto multiple levels. For example, the <head> and <body> tags are nested inside <html> tag. Similarly, one or more <li> tags may be inside a <ul> tag. In this chapter, we shall find out how to scrape a tag that has one or more children tags nested in it.
Let us consider the following HTML document −
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
In this case, the two <div> tags and a <p> tag has one or more child elements nested inside. Whereas, the <img> and <b> tag donot have any children tags.
The findChildren() method returns a ResultSet of all the children under a tag. So, if a tag doesn't have any children, the ResultSet will be an empty list like [].
Taking this as a cue, the following code finds out the tags under each tag in the document tree and displays the list.
Example - Finding inner tags
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.find_all():
print ("Tag: {} attributes: {}".format(tag.name, tag.attrs))
print ("Child tags: ", tag.findChildren())
print()
Output
Tag: div attributes: {'id': 'outer'}
Child tags: [<div id="inner">
<p>Hello<b>World</b></p>
<img src="logo.jpg"/>
</div>, <p>Hello<b>World</b></p>, <b>World</b>, <img src="logo.jpg"/>]
Tag: div attributes: {'id': 'inner'}
Child tags: [<p>Hello<b>World</b></p>, <b>World</b>, <img src="logo.jpg"/>]
Tag: p attributes: {}
Child tags: [<b>World</b>]
Tag: b attributes: {}
Child tags: []
Tag: img attributes: {'src': 'logo.jpg'}
Child tags: []
Beautiful Soup - Parsing Tables
In addition to a textual content, a HTML document may also have a structured data in the form of HTML tables. With Beautiful Soup, we can extract the tabular data in Python objects such as list or dictionary, if required store it in databases or spreadsheets, and perform processing. In this chapter, we shall parse HTML table using Beautiful Soup.
Although Beautiful Soup doesn't any special function or method for extracting table data, we can achieve it by simple scraping techniques. Just like any table, say in SQL or spreadsheet, HTML table consists of rows and columns.
HTML has <table> tag to build a tabular structure. There are one or more nested <tr> tags one each for a row. Each row consists of <td> tags to hold the data in each cell of the row. First row usually is used for column headings, and the headings are placed in <th> tag instead of <td>
Following HTML script renders a simple table on the browser window −
<html>
<body>
<h2>Beautiful Soup - Parse Table</h2>
<table border="1">
<tr>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr class='data'>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr class='data'>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
Note that, the appearance of data rows is customized with a CSS class data, in order to distinguish it from the header row.
We shall now see how to parse the table data. First, we obtain the document tree in the BeautifulSoup object. Then collect all the column headers in a list.
Example - Parsing a table data
tbltag = soup.find('table')
headers = []
headings = tbltag.find_all('th')
for h in headings: headers.append(h.string)
The data row tags with class='data' attribute following the header row are then fetched. A dictionary object with column header as key and corresponding value in each cell is formed and appended to a list of dict objects.
rows = tbltag.find_all_next('tr', {'class':'data'})
trows=[]
for i in rows:
row = {}
data = i.find_all('td')
n=0
for j in data:
row[headers[n]] = j.string
n+=1
trows.append(row)
A list of dictionary objects is collected in trows. You can then use it for different purposes such as storing in a SQL table, saving as a JSON or pandas dataframe object.
The complete code is given below −
markup = """
<html>
<body>
<p>Beautiful Soup - Parse Table</p>
<table>
<tr>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr class='data'>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr class='data'>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser")
tbltag = soup.find('table')
headers = []
headings = tbltag.find_all('th')
for h in headings: headers.append(h.string)
print (headers)
rows = tbltag.find_all_next('tr', {'class':'data'})
trows=[]
for i in rows:
row = {}
data = i.find_all('td')
n=0
for j in data:
row[headers[n]] = j.string
n+=1
trows.append(row)
print (trows)
Output
[{'Name': 'Ravi', 'Age': '23', 'Marks': '67'}, {'Name': 'Anil', 'Age': '27', 'Marks': '84'}]
Beautiful Soup - Selecting nth Child
HTML is characterized by the hierarchical order of tags. For example, the <html> tag encloses <body> tag, inside which there may be a <div> tag further may have <ul> and <li> elements nested respectively. The findChildren() method and .children property both return a ResultSet (list) of all the child tags directly under an element. By traversing the list, you can obtain the child located at a desired position, nth child.
The code below uses the children property of a <div> tag in the HTML document. Since the return type of children property is a list iterator, we shall retrieve a Python list from it. We also need to remove the whitespaces and line breaks from the iterator. Once done, we can fetch the desired child. Here the child element with index 1 of the <div> tag is displayed.
Example - Extracting a Child Element
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
children = tag.children
childlist = [child for child in children if child not in ['\n', ' ']]
print (childlist[1])
Output
<p>Python</p>
To use findChildren() method instead of children property, change the statement to
children = tag.findChildren()
There will be no change in the output.
A more efficient approach toward locating nth child is with the select() method. The select() method uses CSS selectors to obtain required PageElements from the current element.
The Soup and Tag objects support CSS selectors through their .css property, which is an interface to the CSS selector API. The selector implementation is handled by the Soup Sieve package, which gets installed along with bs4 package.
The Soup Sieve package defines different types of CSS selectors, namely simple, compound and complex CSS selectors that are made up of one or more type selectors, ID selectors, class selectors. These selectors are defined in CSS language.
There are pseudo class selectors as well in Soup Sieve. A CSS pseudo-class is a keyword added to a selector that specifies a special state of the selected element(s). We shall use :nth-child pseudo class selector in this example. Since we need to select a child from <div> tag at 2nd position, we shall pass :nthchild(2) to the select_one() method.
Example - Extracting second child element
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
child = tag.select_one(':nth-child(2)')
print (child)
Output
<p>Python</p>
We get the same result as with the findChildren() method. Note that the child numbering starts with 1 and not 0 as in case of a Python list.
Beautiful Soup - Search by text inside a Tag
Beautiful Soup provides different means to search for a certain text in the given HTML document. Here, we use the string argument of the find() method for the purpose.
In the following example, we use the find() method to search for the word 'by'
Example - Usage of find() method to search a string
html = '''
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
'''
from bs4 import BeautifulSoup, NavigableString
def search(tag):
if 'by' in tag.text:
return True
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string=search)
print (tag)
Output
<p> DJs flock by when MTV ax quiz prog.</p>
You can find all occurrences of the word with find_all() method
html = '''
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
'''
from bs4 import BeautifulSoup, NavigableString
def search(tag):
if 'by' in tag.text:
return True
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find_all('p', string=search)
print (tag)
Output
[<p> DJs flock by when MTV ax quiz prog.</p>, <p> Junk MTV quiz graced by fox whelps.</p>]
There may be a situation where the required text may be somewhere in a child tag deep inside the document tree. We need to first locate a tag which has no further elements and then check whether the required text is in it.
Example - Searching a text within child tag
html = ''' <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs./p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tags = soup.find_all(lambda tag: len(tag.find_all()) == 0 and "by" in tag.text) for tag in tags: print (tag)
Output
<p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p>
Beautiful Soup - Remove HTML Tags
In this chapter, let us see how we can remove all tags from a HTML document. HTML is a markup language, made up of predefined tags. A tag marks a certain text associated with it so that the browser renders it as per its predefined meaning. For example, the word Hello marked with <b> tag for example <b>Hello</b), is rendered in bold face by the browser.
If we want to filter out the raw text between different tags in a HTML document, we can use any of the two methods - get_text() or extract() in Beautiful Soup library.
The get_text() method collects all the raw text part from the document and returns a string. However, the original document tree is not changed.
In the example below, the get_text() method removes all the HTML tags.
Example - Removing all HTML Tags
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text)
Output
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
Not that the soup object in the above example still contains the parsed tree of the HTML document.
Another approach is to collect the string enclosed in a Tag object before extracting it from the soup object. In HTML, some tags don't have a string property (we can say that tag.string is None for some tags such as <html> or <body>). So, we concatenate strings from all other tags to obtain the plain text out of the HTML document.
Following program demonstrates this approach.
Example - Clearing tags
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all()
string=''
for tag in tags:
#print (tag.name, tag.string)
if tag.string != None:
string=string+tag.string+'\n'
tag.extract()
print ("Document text after removing tags:")
print (string)
print ("Document:")
print (soup)
Output
Document text after removing tags: The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs. Document:
The clear() method removes the inner string of a tag object but doesn't return it. Similarly the decompose() method destroys the tag as well as all its children elements. Hence, these methods are not suitable to retrieve the plain text from HTML document.
Beautiful Soup - Remove All Styles
This chapter explains how to remove all styles from a HTML document. Cascaded style sheets (CSS) are used to control the appearance of different aspects of a HTML document. It includes styling the rendering of text with a specific font, color, alignment, spacing etc. CSS is applied to HTML tags in different ways.
One is to define different styles in a CSS file and include in the HTML script with the <link> tag in the <head> section in the document. For example,
Example of External styling
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
. . .
. . .
</body>
</html>
The different tags in the body part of the HTML script will use the definitions in style.css file
Another approach is to define the style configuration inside the <head> part of the HTML document itself. Tags in the body part will be rendered by using the definitions provided internally.
Example of Internal styling
<html>
<head>
<style>
p {
text-align: center;
color: red;
}
</style>
</head>
<body>
<p>para1.</p>
<p id="para1">para2</p>
<p>para3</p>
</body>
</html>
In either cases, to remove the styles programmatically, simple remove the head tag from the soup object.
from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") soup.head.extract()
Third approach is to define the styles inline by including style attribute in the tag itself. The style attribute may contain one or more style attribute definitions such as color, size etc. For example
<body> <h1 style="color:blue;text-align:center;">This is a heading</h1> <p style="color:red;">This is a paragraph.</p> </body>
To remove such inline styles from a HTML document, you need to check if attrs dictionary of a tag object has style key defined in it, and if yes delete the same.
tags=soup.find_all()
for tag in tags:
if tag.has_attr('style'):
del tag.attrs['style']
print (soup)
Complete Example
The following code removes the inline styles as well as removes the head tag itself, so that the resultant HTML tree will not have any styles left.
html = '''
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1 style="color:blue;text-align:center;">This is a heading</h1>
<p style="color:red;">This is a paragraph.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.head.extract()
tags=soup.find_all()
for tag in tags:
if tag.has_attr('style'):
del tag.attrs['style']
print (soup.prettify())
Output
<html> <body> <h1> This is a heading </h1> <p> This is a paragraph. </p> </body> </html>
Beautiful Soup - Remove All Scripts
One of the often used tags in HTML is the <script> tag. It facilitates embedding a client side script such as JavaScript code in HTML. In this chapter, we will use BeautifulSoup to remove script tags from the HTML document.
The <script> tag has a corresponding </script> tag. In between the two, you may include either a reference to an external JavaScript file, or include JavaScript code inline with the HTML script itself.
To include an external Javascript file, the syntax used is −
<head> <script src="javascript.js"></script> </head>
You can then invoke the functions defined in this file from inside HTML.
Instead of referring to an external file, you can put JavaScipt code inside the HTML within the <script> and </script> code. If it is put inside the <head> section of the HTML document, then the functionality is available throughout the document tree. On the other hand, if put anywhere in the <body> section, the JavaScript functions are available from that point on.
<body>
<p>Hello World</p>
<script>
alert("Hello World")
</script>
</body>
To remove all script tags with Beautiful is easy. You have to collect the list of all script tags from the parsed tree and extract them one by one.
Example - Removing Scripts from HTML Content
html = '''
<html>
<head>
<script src="javascript.js"></scrript>
</head>
<body>
<p>Hello World</p>
<script>
alert("Hello World")
</script>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all('script'):
tag.extract()
print (soup)
Output
<html> <head> </head> </html>
You can also use the decompose() method instead of extract(), the difference being that that the latter returns the thing that was removed, whereas the former just destroys it. For a more concise code, you may also use list comprehension syntax to achieve the soup object with script tags removed, as follows −
[tag.decompose() for tag in soup.find_all('script')]
Beautiful Soup - Remove Empty Tags
In HTML, many of the tags have an opening and closing tag. Such tags are mostly used for defining the formatting properties, such as <b> and </b>, <h1> and </h1> etc. There are some self-closing tags also which don't have a closing tag and no textual part. For example <img>, <br>, <input> etc. However, while composing HTML, tags such as <p></p> without any text may be inadvertently inserted. We need to remove such empty tags with the help of Beautiful Soup library functions.
Removing textual tags without any text between opening and closing symbols is easy. You can call extract() method on a tag if length of its inner text is 0.
for tag in tags:
if (len(tag.get_text(strip=True)) == 0):
tag.extract()
However, this would remove tags such as <hr>, <img>, and <input> etc. These are all self-closing or singleton tags. You would not like to close tags that have one or more attributes even if there is no text associated with it. So, you'll have to check if a tag has any attributes and the get_text() returns none.
In the following example, there are both situations where an empty textual tag and some singleton tags are present in the HTML string. The code retains the tags with attributes but removes ones without any text embedded.
Example - Removing empty tags
html ='''
<html>
<body>
<p>Paragraph</p>
<embed type="image/jpg" src="Python logo.jpg" width="300" height="200">
<hr>
<b></b>
<p>
<a href="#">Link</a>
<ul>
<li>One</li>
</ul>
<input type="text" id="fname" name="fname">
<img src="img_orange_flowers.jpg" alt="Flowers">
</body>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags =soup.find_all()
for tag in tags:
if (len(tag.get_text(strip=True)) == 0):
if len(tag.attrs)==0:
tag.extract()
print (soup)
Output
<html> <body> <p>Paragraph</p> <embed height="200" src="Python logo.jpg" type="image/jpg" width="300"/> <p> <a href="#">Link</a> <ul> <li>One</li> </ul> <input id="fname" name="fname" type="text"/> <img alt="Flowers" src="img_orange_flowers.jpg"/> </p> </body> </html>
Note that the original html code has a <p> tag without its enclosing </p>. The parser automatically inserts the closing tag. The position of the closing tag may change if you change the parser to lxml or html5lib.
Beautiful Soup - Remove Child Elements
HTML document is a hierarchical arrangement of different tags, where a tag may have one or more tags nested in it at more than one level. How do we remove the child elements of a certain tag? With BeautifulSoup, it is very easy to do it.
There are two main methods in BeautifulSoup library, to remove a certain tag. The decompose() method and extract() method, the difference being that that the latter returns the thing that was removed, whereas the former just destroys it.
Hence to remove the child elements, call findChildren() method for a given Tag object, and then extract() or decompose() on each.
Consider the following code segment −
soup = BeautifulSoup(fp, "html.parser") soup.decompose() print (soup)
This will destroy the entire soup object itself, which is the parsed tree of the document. Obviously, we would not like to do that.
Now the following code −
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all()
for tag in tags:
for t in tag.findChildren():
t.extract()
In the document tree, <html> is the first tag, and all other tags are its children, hence it will remove all the tags except <html> and </html> in the first iteration of the loop itself.
More effective use of this can be done if we want to remove the children of a specific tag. For example, you may want to remove the header row of a HTML table.
Example - Removing child elements
The following example, an HTML script has a table with first <tr> element having headers marked by <th> tag.
We can use the following Python code to remove all the children elements of <tr> tag with <th> cells.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Beautiful Soup - Remove Child Elements</h2>
<table border="1">
<tr class='header'>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all('tr', {'class':'header'})
for tag in tags:
for t in tag.findChildren():
t.extract()
print (soup)
Output
<html> <body> <h2>Beautiful Soup - Parse Table</h2> <table border="1"> <tr class="header"> </tr> <tr> <td>Ravi</td> <td>23</td> <td>67</td> </tr> <tr> <td>Anil</td> <td>27</td> <td>84</td> </tr> </table> </body> </html>
It can be seen that the <th> elements have been removed from the parsed tree
Beautiful Soup - find() method vs find_all() method
Beautiful Soup library includes find() as well as find_all() methods. Both methods are one of the most frequently used methods while parsing HTML or XML documents. From a particular document tree You often need to locate a PageElement of a certain tag type, or having certain attributes, or having a certain CSS style etc. These criteria are given as argument to both find() and find_all() methods. The main point of difference between the two is that while find() locates the very first child element that satisfies the criteria, find_all() method searches for all the children elements of the criteria.
The find() method is defined with following syntax −
Syntax
find(name, attrs, recursive, string, **kwargs)
The name argument specifies a filter on tag name. With attrs, a filter on tag attribute values can be set up. The recursive argument forces a recursive search if it is True. You can pass variable kwargs as dictionary of filters on attribute values.
soup.find(id = 'nm')
soup.find(attrs={"name":'marks'})
The find_all() method takes all the arguments as for the find() method, in addition there is a limit argument. It is an integer, restricting the search the specified number of occurrences of the given filter criteria. If not set, find_all() searches for the criteria among all the children under the said PageElement.
soup.find_all('input')
lst=soup.find_all('li', limit =2)
If the limit argument for find_all() method is set to 1, it virtually acts as find() method.
The return type of both the methods differs. The find() method returns either a Tag object or a NavigableString object first found. The find_all() method returns a ResultSet consisting of all the PageElements satisfying the filter criteria.
Here is an example that demonstrates the difference between find and find_all methods.
Example - Checking find() vs find_all() method
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
ret1 = soup.find('input')
ret2 = soup.find_all ('input')
print (ret1, 'Return type of find:', type(ret1))
print (ret2)
print ('Return tyoe find_all:', type(ret2))
#set limit =1
ret3 = soup.find_all ('input', limit=1)
print ('find:', ret1)
print ('find_all:', ret3)
Output
<input id="nm" name="name" type="text"/> Return type of find: <class 'bs4.element.Tag'> [<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>] Return tyoe find_all: <class 'bs4.element.ResultSet'> find: <input id="nm" name="name" type="text"/> find_all: [<input id="nm" name="name" type="text"/>]
Beautiful Soup - Specifying the Parser
A HTML document tree is parsed into an object of BeautifulSoup class. The constructor of this class needs the mandatory argument as the HTML string or a file object pointing to the html file. The constructor has all other optional arguments, important being features.
BeautifulSoup(markup, features)
Here markup is a HTML string or file object. The features parameter specifies the parser to be used. It may be a specific parser such as "lxml", "lxml-xml", "html.parser", or "html5lib; or type of markup to be used ("html", "html5", "xml").
If the features argument is not given, BeautifulSoup chooses the best HTML parser that's installed. Beautiful Soup ranks lxml's parser as being the best, then html5lib's, then Python's built-in parser.
You can specify one of the following −
The type of markup you want to parse. Beautiful Soup currently supports are "html", "xml", and "html5".
The name of the parser library to be used. Currently supported options are "lxml", "html5lib", and "html.parser" (Python's built-in HTML parser).
To install lxml or html5lib parser, use the command −
pip3 install lxml pip3 install html5lib
These parsers have their advantages and disadvantages as shown below −
Parser: Python's html.parser
Usage − BeautifulSoup(markup, "html.parser")
Advantages
- Batteries included
- Decent speed
- Lenient (As of Python 3.2)
Disadvantages
- Not as fast as lxml, less lenient than html5lib.
Parser: lxml's HTML parser
Usage − BeautifulSoup(markup, "lxml")
Advantages
- Very fast
- Lenient
Disadvantages
- External C dependency
Parser: lxml's XML parser
Usage − BeautifulSoup(markup, "lxml-xml")
Or BeautifulSoup(markup, "xml")
Advantages
- Very fast
- The only currently supported XML parser
Disadvantages
- External C dependency
Parser: html5lib
Usage − BeautifulSoup(markup, "html5lib")
Advantages
- Extremely lenient
- Parses pages the same way a web browser does
- Creates valid HTML5
Disadvantages
- Very slow
- External Python dependency
Different parsers will create different parse trees from the same document. The biggest differences are between the HTML parsers and the XML parsers. Here's a short document, parsed as HTML −
Example - Usage of html parser
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a><b /></a>", "html.parser")
print (soup)
Output
<a><b></b></a>
An empty <b /> tag is not valid HTML. Hence the parser turns it into a <b></b> tag pair.
The same document is now parsed as XML. Note that the empty <b /> tag is left alone, and that the document is given an XML declaration instead of being put into an <html> tag.
Example - Usage of xml parser
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a><b /></a>", "xml")
print (soup)
Output
<?xml version="1.0" encoding="utf-8"?> <a><b/></a>
In case of a perfectly-formed HTML document, all HTML parsers result in similar parsed tree though one parser will be faster than another.
However, if HTML document is not perfect, there will be different results by different types of parsers. See how the results differ when "<a></p>" is parsed with different parsers −
Example - Usage of lxml parser
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "lxml")
print (soup)
Output
<html><body><a></a></body></html>
Note that the dangling </p> tag is simply ignored.
Example - html5lib parser
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "html5lib")
print (soup)
Output
<html><head></head><body><a><p></p></a></body></html>
The html5lib pairs it with an opening <p> tag. This parser also adds an empty <head> tag to the document.
Example - Usage of built-in parser
Built in from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "html.parser")
print (soup)
Output
<a></a>
This parser also ignores the closing </p> tag. But this parser makes no attempt to create a well-formed HTML document by adding a <body> tag, doesn't even bother to add an <html> tag.
The html5lib parser uses techniques that are part of the HTML5 standard, so it has the best claim on being the "correct" way.
Beautiful Soup - Comparing the Objects
As per the beautiful soup, two navigable string or tag objects are equal if they represent the same HTML/XML markup.
Now let us see the below example, where the two <b> tags are treated as equal, even though they live in different parts of the object tree, because they both look like "<b>Java</b>".
Example - Comparing navigable strings
from bs4 import BeautifulSoup
markup = "<p>Learn <i>Python</i>, <b>Java</b>, advanced <i>Python</i> and advanced <b>Java</b>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
b1 = soup.find('b')
b2 = b1.find_next('b')
print(b1== b2)
print(b1 is b2)
Output
True False
In the following examples, two NavigableString objects are compared.
Example - Comparing NavigableString objects
from bs4 import BeautifulSoup
markup = "<p>Learn <i>Python</i>, <b>Java</b>, advanced <i>Python</i> and advanced <b>Java</b>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
i2 = i1.find_next('i')
print(i1.string== i2.string)
print(i1.string is i2.string)
Output
True False
Beautiful Soup - Copying Objects
To create a copy of any tag or NavigableString, use copy() function from the copy module from Python's standard library.
Example - Copying a tag
from bs4 import BeautifulSoup
import copy
markup = "<p>Learn <b>Python, Java</b>, <i>advanced Python and advanced Java</i>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
icopy = copy.copy(i1)
print (icopy)
Output
<i>advanced Python and advanced Java</i>
Example - Comparing copied tags
Although the two copies (original and copied one) contain the same markup however, the two do not represent the same object.
from bs4 import BeautifulSoup
import copy
markup = "<p>Learn <b>Python, Java</b>, <i>advanced Python and advanced Java</i>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
icopy = copy.copy(i1)
print (i1 == icopy)
print (i1 is icopy)
Output
True False
Example - Comparing copied tag parent
The copied object is completely detached from the original Beautiful Soup object tree, just as if extract() had been called on it.
from bs4 import BeautifulSoup
import copy
markup = "<p>Learn <b>Python, Java</b>, <i>advanced Python and advanced Java</i>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
icopy = copy.copy(i1)
print (icopy.parent)
Output
None
Beautiful Soup - Get Tag Position
The Tag object in Beautiful Soup possesses two useful properties that give the information about its position in the HTML document. They are −
sourceline − line number at which the tag is found
sourcepos − The starting index of the tag in the line in which it is found.
These properties are supported by the html.parser which is Python's in-built parser and html5lib parser. They are not available when you are using lmxl parser.
In the following example, a HTML string is parsed with html.parser and we find the line number and position of <p> tag in the HTML string.
Example - Printing Position of Tag
html = '''
<html>
<body>
<p>Web frameworks</p>
<ul>
<li>Django</li>
<li>Flask</li>
</ul>
<p>GUI frameworks</p>
<ol>
<li>Tkinter</li>
<li>PyQt</li>
</ol>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
p_tags = soup.find_all('p')
for p in p_tags:
print (p.sourceline, p.sourcepos, p.string)
Output
4 0 Web frameworks 9 0 GUI frameworks
For html.parser, these numbers represent the position of the initial less-than sign, which is 0 in this example. It is slightly different when html5lib parser is used.
Example - Position of Tag with html5lib parser
html = '''
<html>
<body>
<p>Web frameworks</p>
<ul>
<li>Django</li>
<li>Flask</li>
</ul>
<p>GUI frameworks</p>
<ol>
<li>Tkinter</li>
<li>PyQt</li>
</ol>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html5lib')
li_tags = soup.find_all('li')
for l in li_tags:
print (l.sourceline, l.sourcepos, l.string)
Output
6 3 Django 7 3 Flask 11 3 Tkinter 12 3 PyQt
When using html5lib, the sourcepos property returns the position of the final greater-than sign.
Beautiful Soup - Encoding
All HTML or XML documents are written in some specific encoding like ASCII or UTF-8. However, when you load that HTML/XML document into BeautifulSoup, it has been converted to Unicode.
Example - Checking Unicode
from bs4 import BeautifulSoup markup = "<p>I will display £</p>" soup = BeautifulSoup(markup, "html.parser") print (soup.p) print (soup.p.string)
Output
<p>I will display £</p> I will display £
Above behavior is because BeautifulSoup internally uses the sub-library called Unicode, Dammit to detect a document's encoding and then convert it into Unicode.
However, not all the time, the Unicode, Dammit guesses correctly. As the document is searched byte-by-byte to guess the encoding, it takes lot of time. You can save some time and avoid mistakes, if you already know the encoding by passing it to the BeautifulSoup constructor as from_encoding.
Below is one example where the BeautifulSoup misidentifies, an ISO-8859-8 document as ISO-8859-7 −
Example - Misidentification of encoding
from bs4 import BeautifulSoup markup = b"<h1>\xed\xe5\xec\xf9</h1>" soup = BeautifulSoup(markup, 'html.parser') print (soup.h1) print (soup.original_encoding)
Output
<h1>νεμω</h1> iso-8859-7
To resolve above issue, pass it to BeautifulSoup using from_encoding −
Example - Using from_encoding
from bs4 import BeautifulSoup markup = b"<h1>\xed\xe5\xec\xf9</h1>" soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8") print (soup.h1) print (soup.original_encoding)
Output
<h1>םולש</h1> iso-8859-8
Another new feature added from BeautifulSoup 4.4.0 is, exclude_encoding. It can be used, when you don't know the correct encoding but sure that Unicode, Dammit is showing wrong result.
soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])
Output encoding
The output from a BeautifulSoup is UTF-8 document, irrespective of the entered document to BeautifulSoup. Below a document, where the polish characters are there in ISO-8859-2 format.
Example - Using ISO-8859-2 format
markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
</BODY>
</HTML>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8")
print (soup.prettify())
Output
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
</body>
</html>
In the above example, if you notice, the <meta> tag has been rewritten to reflect the generated document from BeautifulSoup is now in UTF-8 format.
If you don't want the generated output in UTF-8, you can assign the desired encoding in prettify().
markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
</BODY>
</HTML>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8")
print(soup.prettify("latin-1"))
Output
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'
In the above example, we have encoded the complete document, however you can encode, any particular element in the soup as if they were a python string −
markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
<p>My first paragraph.</p>
<h1>My First Heading</h1>
</BODY>
</HTML>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8")
print(soup.p.encode("latin-1"))
print(soup.h1.encode("latin-1"))
Output
b'<p>My first paragraph.</p>' b'<h1>My First Heading</h1>'
Any characters that can't be represented in your chosen encoding will be converted into numeric XML entity references. Below is one such example −
markup = u"<b>\N{SNOWMAN}</b>"
snowman_soup = BeautifulSoup(markup)
tag = snowman_soup.b
print(tag.encode("utf-8"))
Output
b'<b>\xe2\x98\x83</b>'
If you try to encode the above in "latin-1" or "ascii", it will generate "☃", indicating there is no representation for that.
markup = u"<b>\N{SNOWMAN}</b>"
snowman_soup = BeautifulSoup(markup)
tag = snowman_soup.b
print (tag.encode("latin-1"))
print (tag.encode("ascii"))
Output
b'<b>☃</b>' b'<b>☃</b>'
Unicode, Dammit
Unicode, Dammit is used mainly when the incoming document is in unknown format (mainly foreign language) and we want to encode in some known format (Unicode) and also we don't need Beautifulsoup to do all this.
Beautiful Soup - Output Formatting
If the HTML string given to BeautifulSoup constructor contains any of the HTML entities, they will be converted to Unicode characters.
An HTML entity is a string that begins with an ampersand ( & ) and ends with a semicolon ( ; ). They are used to display reserved characters (which would otherwise be interpreted as HTML code). Some of the examples of HTML entities are −
| < | less than | < | < |
| > | greater than | > | > |
| & | ampersand | & | & |
| " | double quote | " | " |
| ' | single quote | ' | ' |
| " | Left Double quote | “ | “ |
| " | Right double quote | ” | ” |
| Pound | £ | £ | |
| yen | ¥ | ¥ | |
| euro | € | € | |
| copyright | © | © |
By default, the only characters that are escaped upon output are bare ampersands and angle brackets. These get turned into "&", "<", and ">"
For others, they'll be converted to Unicode characters.
Example - Unicode Characters Encoding
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (str(soup))
Output
Hello "World!"
If you then convert the document to a bytestring, the Unicode characters will be encoded as UTF-8. You won't get the HTML entities back −
Example - UTF-8 format Encoding
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (soup.encode())
Output
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d'
To change this behavior provide a value for the formatter argument to prettify() method. There are following possible values for the formatter.
formatter="minimal" − This is the default. Strings will only be processed enough to ensure that Beautiful Soup generates valid HTML/XML
formatter="html" − Beautiful Soup will convert Unicode characters to HTML entities whenever possible.
formatter="html5" − it's similar to formatter="html", but Beautiful Soup will omit the closing slash in HTML void tags like "br"
formatter=None − Beautiful Soup will not modify strings at all on output. This is the fastest option, but it may lead to Beautiful Soup generating invalid HTML/XML
Example - Usage of formatter with prettify() method
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.prettify(formatter="minimal"))
print ("html: ")
print(soup.prettify(formatter="html"))
print ("None: ")
print(soup.prettify(formatter=None))
Output
minimal: <p> Il a dit <<Sacr bleu!>> </p> html: <p> Il a dit <<Sacré bleu!>> </p> None: <p> Il a dit <<Sacr bleu!>> </p>
In addition, Beautiful Soup library provides formatter classes. You can pass an object of any of these classes as argument to prettify() method.
HTMLFormatter class − Used to customize the formatting rules for HTML documents.
XMLFormatter class − Used to customize the formatting rules for XML documents.
Beautiful Soup - Pretty Printing
To display the entire parsed tree of an HTML document or the contents of a specific tag, you can use the print() function or call str() function as well.
Example - Printing an Element
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h1>Hello World</h1>", "lxml")
print ("Tree:",soup)
print ("h1 tag:",str(soup.h1))
Output
Tree: <html><body><h1>Hello World</h1></body></html> h1 tag: <h1>Hello World</h1>
The str() function returns a string encoded in UTF-8.
To get a nicely formatted Unicode string, use Beautiful Soup's prettify() method. It formats the Beautiful Soup parse tree so that there each tag is on its own separate line with indentation. It allows to you to easily visualize the structure of the Beautiful Soup parse tree.
Consider the following HTML string.
<p>The quick, <b>brown fox</b> jumps over a lazy dog.</p>
Example - Usage of prettify() method
Using the prettify() method we can better understand its structure −
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.prettify())
Output
<html>
<body>
<p>
The quick,
<b>
brown fox
</b>
jumps over a lazy dog.
</p>
</body>
</html>
Example - Using prettify() on a Tag
You can call prettify() on on any of the Tag objects in the document.
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.b.prettify())
Output
<b> brown fox </b>
The prettify() method is for understanding the structure of the document. However, it should not be used to reformat it, as it adds whitespace (in the form of newlines), and changes the meaning of an HTML document.
He prettify() method can optionally be provided formatter argument to specify the formatting to be used.
Beautiful Soup - NavigableString Class
One of the main objects prevalent in Beautiful Soup API is the object of NavigableString class. It represents the string or text between the opening and closing counterparts of most of the HTML tags. For example, if <b>Hello</b> is the markup to be parsed, Hello is the NavigableString.
NavigableString class is subclassed from the PageElement class in bs4 package, as well as Python's built-in str class. Hence, it inherits the PageElement methods such as find_*(), insert, append, wrap,unwrap methods as well as methods from str class such as upper, lower, find, isalpha etc.
The constructor of this class takes a single argument, a str object.
Example
from bs4 import NavigableString
new_str = NavigableString('world')
You can now use this NavigableString object to perform all kinds of operations on the parsed tree, such as append, insert, find etc.
In the following example, we append the newly created NavigableString object to an existing Tab object.
Example - Appending a NavigableString Object
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_str = NavigableString('world')
tag.append(new_str)
print (soup)
Output
<b>Helloworld</b>
Note that the NavigableString is a PageElement, hence it can be appended to the Soup object also. Check the difference if we do so.
Example - Appending a Page Element
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
new_str = NavigableString('world')
soup.append(new_str)
print (soup)
Output
<b>Hello</b>world
As we can see, the string appears after the <b> tag.
Beautiful Soup offers a new_string() method. Create a new NavigableString associated with this BeautifulSoup object.
Let us new_string() method to create a NavigableString object, and add it to the PageElements.
Example - Usage of new_string() method
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
ns=soup.new_string(' World')
tag.append(ns)
print (tag)
soup.append(ns)
print (soup)
Output
<b>Hello World</b> <b>Hello</b> World
We find an interesting behaviour here. The NavigableString object is added to a tag inside the tree, as well as to the soup object itself. While the tag shows the appended string, but in the soup object, the text World is appended, but it doesn't show in the tag. This is because the new_string() method creates a NavigableString associated with the Soup object.
Beautiful Soup - Convert Object to String
The Beautiful Soup API has three main types of objects. The soup object, the Tag object, and the NavigableString object. Let us find out how we can convert each of these object to string. In Python, string is a str object.
Assuming that we have a following HTML document
html = ''' <p>Hello <b>World</b></p> '''
Let us put this string as argument for BeautifulSoup constructor. The soup object is then typecast to string object with Python's builtin str() function.
The parsed tree of this HTML string will be constructed dpending upon which parser you use. The built-in html parser doesn't add the <html> and <body> tags.
Example - Getting String from an Object
html = ''' <p>Hello <b>World</b></p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (str(soup))
Output
<p>Hello <b>World</b></p>
On the other hand, the html5lib parser constructs the tree after inserting the formal tags such as <html> and <body>
Example - Getting String from an Object using html5lib parser
html = ''' <p>Hello <b>World</b></p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html5lib') print (str(soup))
Output
<html><head></head><body><p>Hello <b>World</b></p> </body></html>
The Tag object has a string property that returns a NavigableString object.
Example - Getting NavigableString
html = '''
<p>Hello <b>World</b></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('b')
obj = (tag.string)
print (type(obj),obj)
Output
string <class 'bs4.element.NavigableString'> World
There is also a Text property defined for Tag object. It returns the text contained in the tag, stripping off all the inner tags and attributes.
If the HTML string is −
html = ''' <p>Hello <div id='id'>World</div></p> '''
We try to obtain the text property of <p> tag
html = '''
<p>Hello <div id='id'>World</div></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p')
obj = (tag.text)
print ( type(obj), obj)
Output
<class 'str'> Hello World
You can also use the get_text() method which returns a string representing the text inside the tag. The function is actually a wrapper arounf the text property as it also gets rid of inner tags and attributes, and returns a string
html = '''
<p>Hello <div id='id'>World</div></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p')
obj = tag.get_text()
print (type(obj),obj)
Output
<class 'str'> Hello World
Beautiful Soup - Convert HTML to Text
One of the important and a frequently required application of a web scraper such as Beautiful Soup library is to extract text from a HTML script. You may need to discard all the tags along with the attributes associated if any with each tag and separate out the raw text in the document. The get_text() method in Beautiful Soup is suitable for this purpose.
Here is a basic example demonstrating the usage of get_text() method. You get all the text from HTML document by removing all the HTML tags.
Example - Usage of get_text() method
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text)
Output
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
Example - Usage of get_text() with separator
The get_text() method has an optional separator argument. In the following example, we specify the separator argument of get_text() method as '#'.
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(separator='#') print(text)
Output
#The quick, brown fox jumps over a lazy dog.# #DJs flock by when MTV ax quiz prog.# #Junk MTV quiz graced by fox whelps.# #Bawds jog, flick quartz, vex nymphs.#
Example - Usage of get_text() with strip
The get_text() method has another argument strip, which can be True or False. Let us check the effect of strip parameter when it is set to True. By default it is False.
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(strip=True) print(text)
Output
The quick, brown fox jumps over a lazy dog.DJs flock by when MTV ax quiz prog.Junk MTV quiz graced by fox whelps.Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - Parsing XML
BeautifulSoup can also parse a XML document. You need to pass fatures='xml' argument to Beautiful() constructor.
Assuming that we have the following xml
Example - Parsing XML
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
The following code parses the given XML file −
from bs4 import BeautifulSoup
xml = """
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
"""
soup = BeautifulSoup(xml, features="xml")
print (soup)
print ('type:', type(soup))
Output
When the above code is executed, you should get the following result −
<?xml version="1.0" encoding="utf-8"?> <books> <book> <title>Python</title> <author>TutorialsPoint</author> <price>400</price> </book> </books> type: <class 'bs4.BeautifulSoup'>
XML parser Error
By default, BeautifulSoup package parses the documents as HTML, however, it is very easy-to-use and handle ill-formed XML in a very elegant manner using beautifulsoup4.
To parse the document as XML, you need to have lxml parser and you just need to pass the "xml" as the second argument to the Beautifulsoup constructor −
soup = BeautifulSoup(markup, "lxml-xml")
or
soup = BeautifulSoup(markup, "xml")
One common XML parsing error is −
AttributeError: 'NoneType' object has no attribute 'attrib'
This might happen in case, some element is missing or not defined while using find() or findall() function.
Beautiful Soup - Error Handling
While trying to parse HTML/XML document with Beautiful Soup, you may encounter errors, not from your script but from the structure of the snippet because the BeautifulSoup API throws an error.
By default, BeautifulSoup package parses the documents as HTML, however, it is very easy-to-use and handle ill-formed XML in a very elegant manner using beautifulsoup4.
To parse the document as XML, you need to have lxml parser and you just need to pass the "xml" as the second argument to the Beautifulsoup constructor −
soup = BeautifulSoup(markup, "lxml-xml")
or
soup = BeautifulSoup(markup, "xml")
One common XML parsing error is −
AttributeError: 'NoneType' object has no attribute 'attrib'
This might happen in case, some element is missing or not defined while using find() or findall() function.
Apart from the above mentioned parsing errors, you may encounter other parsing issues such as environmental issues where your script might work in one operating system but not in another operating system or may work in one virtual environment but not in another virtual environment or may not work outside the virtual environment. All these issues may be because the two environments have different parser libraries available.
It is recommended to know or check your default parser in your current working environment. You can check the current default parser available for the current working environment or else pass explicitly the required parser library as second arguments to the BeautifulSoup constructor.
As the HTML tags and attributes are case-insensitive, all three HTML parsers convert tag and attribute names to lowercase. However, if you want to preserve mixed-case or uppercase tags and attributes, then it is better to parse the document as XML.
UnicodeEncodeError
Let us look into below code segment −
Example - Checking Unicode Error
soup = BeautifulSoup(response, "html.parser") print (soup)
Output
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'
Above problem may be because of two main situations. You might be trying to print out a unicode character that your console doesn't know how to display. Second, you are trying to write to a file and you pass in a Unicode character that's not supported by your default encoding.
One way to resolve above problem is to encode the response text/character before making the soup to get the desired result, as follows −
responseTxt = response.text.encode('UTF-8')
KeyError: [attr]
It is caused by accessing tag['attr'] when the tag in question doesn't define the attr attribute. Most common errors are: "KeyError: 'href'" and "KeyError: 'class'". Use tag.get('attr') if you are not sure attr is defined.
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback action
AttributeError
You may encounter AttributeError as follows −
AttributeError: 'list' object has no attribute 'find_all'
The above error mainly occurs because you expected find_all() return a single tag or string. However, soup.find_all returns a python list of elements.
All you need to do is to iterate through the list and catch data from those elements.
To avoid the above errors when parsing a result, that result will be bypassed to make sure that a malformed snippet isn't inserted into the databases −
except(AttributeError, KeyError) as er: pass
Beautiful Soup - Trouble Shooting
If you run into problems while trying to parse a HTML/XML document, it is more likely because how the parser in use is interpreting the document. To help you locate and correct the problem, Beautiful Soup API provides a dignose() utility.
The diagnose() method in Beautiful Soup is a diagnostic suite for isolating common problems. If you're facing difficulty in understanding what Beautiful Soup is doing to a document, pass the document as argument to the diagnose() function. A report showing you how different parsers handle the document, and tell you if you're missing a parser.
The diagnose() method is defined in bs4.diagnose module. Its output starts with a message as follows −
Example - Usage of diagnose() method
diagnose(markup)
Output
Diagnostic running on Beautiful Soup 4.12.2 Python version 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] Found lxml version 4.9.2.0 Found html5lib version 1.1 Trying to parse your markup with html.parser Here's what html.parser did with the markup:
If it doesn't find any of these parsers, a corresponding message also appears.
I noticed that html5lib is not installed. Installing it may help.
If the HTML document fed to diagnose() method is perfectly formed, the parsed tree by any of the parsers will be identical. However if it is not properly formed, then different parser interprets differently. If you don't get the tree as you anticipate, changing the parser might help.
Sometimes, you may have chosen HTML parser for a XML document. The HTML parsers add all the HTML tags while parsing the document incorrectly. Looking at the output, you will realize the error and can help in correcting.
If Beautiful Soup raises HTMLParser.HTMLParseError, try and change the parser.
parse errors are HTMLParser.HTMLParseError: malformed start tag and HTMLParser.HTMLParseError: bad end tag are both generated by Python's built-in HTML parser library, and the solution is to install lxml or html5lib.
If you encounter SyntaxError: Invalid syntax (on the line ROOT_TAG_NAME = '[document]'), it is caused by running an old Python 2 version of Beautiful Soup under Python 3, without converting the code.
The ImportError with message No module named HTMLParser is because of an old Python 2 version of Beautiful Soup under Python 3.
While, ImportError: No module named html.parser - is caused by running the Python 3 version of Beautiful Soup under Python 2.
If you get ImportError: No module named BeautifulSoup - more often than not, it is because of running Beautiful Soup 3 code on a system that doesn't have BS3 installed. Or, by writing Beautiful Soup 4 code without knowing that the package name has changed to bs4.
Finally, ImportError: No module named bs4 - is due to the fact that you are trying a Beautiful Soup 4 code on a system that doesn't have BS4 installed.
Beautiful Soup - Porting Old Code
You can make the code from earlier version of Beautiful Soup compatible with the lates version by making following change in the import statement −
Example
from BeautifulSoup import BeautifulSoup #becomes this: from bs4 import BeautifulSoup
If you get the ImportError "No module named BeautifulSoup", it means you're trying to run Beautiful Soup 3 code, but you only have Beautiful Soup 4 installed. Similarly, If you get the ImportError "No module named bs4", because you're trying to run Beautiful Soup 4 code, but you only have Beautiful Soup 3 installed.
Beautiful Soup 3 used Python's SGMLParser, a module that has been removed in Python 3.0. Beautiful Soup 4 uses html.parser by default, but you can also use lxml or html5lib.
Although BS4 is mostly backwards-compatible with BS3, most of its methods have been deprecated and given new names for PEP 8 compliance.
Here are a few examples −
replaceWith -> replace_with findAll -> find_all findNext -> find_next findParent -> find_parent findParents -> find_parents findPrevious -> find_previous getText -> get_text nextSibling -> next_sibling previousSibling -> previous_sibling
Beautiful Soup - contents Property
Description
The contents property is available with the Soup object as well as Tag object. It returns a list everything that is contained inside the object, all the immediate child elements and text nodes (i.e. Navigable String).
Syntax
Tag.contents
Return value
The contents property returns a list of child elements and strings in the Tag/Soup object,.
Example - Getting Contents of a Tag object
from bs4 import BeautifulSoup
markup = '''
<div id="Languages">
<p>Java</p>
<p>Python</p>
<p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
print (tag.contents)
Output
['\n', <p>Java</p>, '\n', <p>Python</p>, '\n', <p>C++</p>, '\n']
Example - Getting Contents of Entire Document
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print (soup.contents)
Output
['\n', <div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>, '\n']
Example - Case of AttributeError
Note that a NavigableString object doesn't have contents property. It throws AttributeError if we try to access the same.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
s=tag.contents[0]
print (s.contents)
Output
Traceback (most recent call last):
File "C:\Users\user\BeautifulSoup\2.py", line 11, in <module>
print (s.contents)
^^^^^^^^^^
File "C:\Users\user\BeautifulSoup\Lib\site-packages\bs4\element.py", line 984, in __getattr__
raise AttributeError(
AttributeError: 'NavigableString' object has no attribute 'contents'
Beautiful Soup - children Property
Description
The Tag object in Beautiful Soup library has children property. It returns a generator used to iterate over the immediate child elements and text nodes (i.e. Navigable String).
Syntax
Tag.children
Return value
The property returns a generator with which you can iterate over direct children of the PageElement.
Example - Getting Children of a Tag
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
children = tag.children
for child in children:
print (child)
Output
<p>Java</p> <p>Python</p> <p>C++</p>
Example - Getting Children of soup Object
The soup object too bears the children property.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
children = soup.children
for child in children:
print (child)
Output
<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>
Example - Getting Children of a p Tag
In the following example, we append NavigableString objects to the <p> Tag and get the list of children.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
soup.p.extend(['and', 'JavaScript'])
children = soup.p.children
for child in children:
print (child)
Output
Java and JavaScript
Beautiful Soup - string Property
Description
In Beautiful Soup, the soup and Tag object has a convenience property - string property. It returns a single string within a PageElement, Soup or Tag. If this element has a single string child, then a NavigableString corresponding to it is returned. If this element has one child tag, return value is the 'string' attribute of the child tag, and if element itself is a string, (with no children), then the string property returns None.
Syntax
Tag.string
Example - String Property of First Tag
The following code has the HTML string with a <div> tag that encloses three <p> elements. We find the string property of first <p> tag.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
navstr = tag.string
print (navstr, type(navstr))
nav_str = str(navstr)
print (nav_str, type(nav_str))
Output
Java <class 'bs4.element.NavigableString'> Java <class 'str'>
The string property returns a NavigableString. It can be cast to a regular Python string with str() function
Example - String property of inner children
The string property of an element with children elements inside, returns None. Check with the <div> tag.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
navstr = tag.string
print (navstr)
Output
None
Beautiful Soup - strings Property
Description
For any PageElement having more than one children, the inner text of each can be fetched by the strings property. Unlike the string property, strings handles the case when the element contains multiple children. The strings property returns a generator object. It yields a sequence of NavigableStrings corresponding to each of the child elements.
Syntax
Tag.strings
Example - Strings property of soup Object
You can retrieve the value of strings property for soup as well as a tag object. In the following example, the soup object's stings property is checked.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print ([string for string in soup.strings])
Output
['\n', '\n', 'Java', ' ', 'Python', ' ', 'C++', '\n', '\n']
Note the line breaks and white spaces in the list.We can remove them with stripped_strings property.
Example - Strings property of tag
We now obtain a generator object returned by the strings property of <div> tag. With a loop, we print the strings.
tag = soup.div navstrs = tag.strings for navstr in navstrs: print (navstr)
Output
Java Python C++
Note that the line breaks and whiteapces have appeared in the output, which can be removed with stripped_strings property.
Beautiful Soup - stripped_strings Property
Description
The stripped_strings property of a Tag/Soup object gives the return similar to strings property, except for the fact that the extra line breaks and whitespaces are stripped off. Hence, it can be said that the stripped_strings property results in a generator of NavigableString objects of the inner elements belonging to the object in use.
Syntax
Tag.stripped_strings
Example - Stripping extra breaks
In the example below, the strings of all the elements in the document tree parsed in a BeautifulSoup object are displayed after applying the stripping.
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print ([string for string in soup.stripped_strings])
Output
['Java', 'Python', 'C++']
Compared to the output of strings property, you can see that the line breaks and whitespaces are removed.
Example - Extracting NavigableString of child
Here we extract the NavigableStrings of each of the child elements under the <div> tag.
tag = soup.div navstrs = tag.stripped_strings for navstr in navstrs: print (navstr)
Output
Java Python C++
Beautiful Soup - descendants Property
Method Description
With the descendants property of a PageElement object in Beautiful Soup API you can traverse the list of all children under it. This property returns a generator object, with which the children elements can be retrieved in a breadth-first sequence.
While searching a tree structure, the Breadth-first traversal starts at the tree root and explores all nodes at the present depth prior to moving on to the nodes at the next depth level.
Syntax
tag.descendants
Return value
The descendants property returns a generator object.
Example - Getting All Children of soup Object
In the code below, we have a HTML document with nested unordered list tags. We scrape through the children elements parsed in breadth-first manner.
html = '''
<ul id='outer'>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Anil</li>
<li class="submenu">Milind</li>
</ul>
</ul>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('ul', {'id': 'outer'})
tags = soup.descendants
for desc in tags:
print (desc)
Output
<ul id="outer"> <li class="mainmenu">Accounts</li> <ul> <li class="submenu">Anand</li> <li class="submenu">Mahesh</li> </ul> <li class="mainmenu">HR</li> <ul> <li class="submenu">Anil</li> <li class="submenu">Milind</li> </ul> </ul> <li class="mainmenu">Accounts</li> Accounts <ul> <li class="submenu">Anand</li> <li class="submenu">Mahesh</li> </ul> <li class="submenu">Anand</li> Anand <li class="submenu">Mahesh</li> Mahesh <li class="mainmenu">HR</li> HR <ul> <li class="submenu">Anil</li> <li class="submenu">Milind</li> </ul> <li class="submenu">Anil</li> Anil <li class="submenu">Milind</li> Milind
Example - Getting Descendants of Head Tag
In the following example, we list out the descendants of <head> tag
html = """ <html><head><title>TutorialsPoint</title></head> <body> <p>Hello World</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head for element in tag.descendants: print (element)
Output
<title>TutorialsPoint</title> TutorialsPoint
Beautiful Soup - parent Property
Description
The parent property in BeautifulSoup library returns the immediate parent element of the said PegeElement. The type of the value returned by the parents property is a Tag object. For the BeautifulSoup object, its parent is a document object
Syntax
Element.parent
Return value
The parent property returns a Tag object. For Soup object, it returns document object
Example - Usage of parent Property
This example uses .parent property to find the immediate parent element of the first <p> tag in the example HTML string.
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<p>Hello World</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.p
print (tag.parent.name)
Output
body
Example - Checking parent property of Title tag
In the following example, we see that the <title> tag is enclosed inside a <head> tag. Hence, the parent property for <title> tag returns the <head> tag.
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<p>Hello World</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.title
print (tag.parent)
Output
<head><title>TutorialsPoint</title></head>
Example - Usage of parent property with different Parsers
The behaviour of Python's built-in HTML parser is a little different from html5lib and lxml parsers. The built-in parser doesn't try to build a perfect document out of the string provided. It doesn't add additional parent tags like body or html if they don't exist in the string. On the other hand, html5lib and lxml parsers add these tags to make the document a perfect HTML document.
html = """ <p><b>Hello World</b></p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.p.parent.name) soup = BeautifulSoup(html, 'html5lib') print (soup.p.parent.name)
Output
[document] Body
As the HTML parser doesn't add additional tags, the parent of parsed soup is document object. However, when we use html5lib, the parent tag's name property is Body.
Beautiful Soup - parents Property
Description
The parents property in BeautifulSoup library retrieves all the parent elements of the said PegeElement in a recursive manner. The type of the value returned by the parents property is a generator, with the help of which we can list out the parents in the down-to-up order.
Syntax
Element.parents
Return value
The parents property returns a generator object.
Example - Usage of parents property
This example uses .parents to travel from an <a> tag buried deep within the document, to the very top of the document. In the following code, we track the parents of the first <p> tag in the example HTML string.
html = """ <html><head><title>TutorialsPoint</title></head> <body> <p>Hello World</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.p for element in tag.parents: print (element.name)
Output
body html [document]
Note that the parent to the BeautifulSoup object is [document].
Example - Using parents property to iterate tags
In the following example, we see that the <b> tag is enclosed inside a <p> tag. The two div tags above it have an id attribute. We try to print the only those elements having id attribute. The has_attr() method is used for the purpose.
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.b
for parent in tag.parents:
if parent.has_attr("id"):
print(parent["id"])
Output
inner outer
Beautiful Soup - next_sibling Property
Description
The HTML tags appearing at the same indentation level are called siblings. The next_sibling property of the PageElement returns next tag at the same level, or under the same parent.
Syntax
element.next_sibling
Return type
The next_sibling property returns a PageElement, a Tag or a NavigableString object.
Example - Usage of next_sibling property
The index.html wage page consists of a HTML form with three input elements each with a name attribute. In the following example, the next sibling of an input tag with name attribute as nm is located.
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_previous())
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'nm'})
sib = tag.next_sibling
print (sib)
Output
<input id="nm" name="name" type="text"/>
Example - Using next_sibling of particular tag
In the next example, we have a HTML document with a couple of tags inside a <p> tag. The next_sibling property returns the tag next to <b> tag in it.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.next_sibling)
Output
next: <i>Python</i>
Example - Using next_sibling with tags at same level
Consider the HTML string in the following document. It has two <p> tags at the same level. The next_sibling of first <p> should give the second <p> tag's contents.
from bs4 import BeautifulSoup
html = '''
<p><b>Hello</b><i>Python</i></p>
<p>TutorialsPoint</p>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.p
print ("next:",tag1.next_sibling)
Output
next:
The blank line after the word next: is unexpected. But that's because of the \n character after the first <p> tag. Change the print statement as shown below to obtain the contents of the next_sibling
from bs4 import BeautifulSoup
html = '''
<p><b>Hello</b><i>Python</i></p>
<p>TutorialsPoint</p>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.p
print ("next:",tag1.next_sibling.next_sibling)
Output
next: <p>TutorialsPoint</p>
Beautiful Soup - previous_sibling Property
Description
The HTML tags appearing at the same indentation level are called siblings. The previous_sibling property of the PageElement returns a previous tag (a tag appearing before the current tag) at the same level, or under the same parent. This property encapsulates the find_previous_sibling() method.
Syntax
element.previous_sibling
Return type
The previous_sibling property returns a PageElement, a Tag or a NavigableString object.
Example - Usage of previous_sibling property
In the following code, the HTML string consists of two adjacent tags inside a <p> tag. It shows the sibling tag for <b> tag appearing before it.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag = soup.i
sibling = tag.previous_sibling
print (sibling)
Output
<b>Hello</b>
Example - Using previous_sibling property for input fields
We are using the index.html file for parsing. The page contains a HTML form with three input elements. Which element is a previous sibling of input element with its id attribute as age? The following code shows it −
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'id':'age'})
sib = tag.previous_sibling.previous_sibling
print (sib)
Output
<input id="nm" name="name" type="text"/>
Example - Finding a Previous Sibling for P tag
First we find the <p> tag containing the string 'Tutorial' and then finds a tag previous to it.
from bs4 import BeautifulSoup
html = '''
<p>Excellent</p><p>Python</p><p>Tutorial</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string='Tutorial')
print (tag.previous_sibling)
Output
<p>Python</p>
Beautiful Soup - next_siblings Property
Description
The HTML tags appearing at the same indentation level are called siblings. The next_siblings property in Beautiful Soup returns returns a generator object used to iterate over all the subsequent tags and strings under the same parent.
Syntax
element.next_siblings
Return type
The next_siblings property returns a generator of sibling PageElements.
Example - Usage of next_siblings property
In HTML form code in index.html contains three input elements. Following script uses next_siblings property to collect next siblings of an input element with id attribute as nm
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'id':'nm'})
siblings = tag.next_siblings
print (list(siblings))
Output
['\n', <input id="age" name="age" type="text"/>, '\n', <input id="marks" name="marks" type="text"/>, '\n']
Example - Traversing Next Sibling Tags
Let us use the following HTML snippet for this purpose −
Use the following code to traverse next siblings tags.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.b
print ("next siblings:")
for tag in tag1.next_siblings:
print (tag)
Output
next siblings: <i>Python</i> <u>Tutorial</u>
Example - next sibling of head tag
Next example shows that the <head> tag has only one next sibling in the form of body tag.
html = '''
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Excellent</p><p>Python</p><p>Tutorial</p>
</body>
</head>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.head.next_siblings
print ("next siblings:")
for tag in tags:
print (tag)
Output
next siblings: <body> <p>Excellent</p><p>Python</p><p>Tutorial</p> </body>
The additional lines are because of the line breaks in the generator.
Beautiful Soup - previous_siblings Property
Description
The HTML tags appearing at the same indentation level are called siblings. The previous_siblings property in Beautiful Soup returns returns a generator object used to iterate over all the tags and strings before the current tag, under the same parent. This gives he similar output as find_previous_siblings() method.
Syntax
element.previous_siblings
Return type
The previous_siblings property returns a generator of sibling PageElements.
Example - Usage of previous_siblings Property
The following example parses the given HTML string that has a few tags embedded inside the outer <p> tag. The previous siblings of the <u> tag are fetched with the help of previous_siblings property.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.u
print ("previous siblings:")
for tag in tag1.previous_siblings:
print (tag)
Output
previous siblings: <i>Python</i> <b>Excellent</b>
Example - Getting previous siblings on input elements
Considering there are three input elements in the HTML content. We find out what are the sibling tags previous to the one with id set as marks, and under the <form> tag.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sibs = tag.previous_siblings
print ("previous siblings:")
for sib in sibs:
print (sib)
Output
previous siblings: <input id="age" name="age" type="text"/> <input id="nm" name="name" type="text"/>
Example - Usage of previous_sublings of body tag
The top level <html> tag always has two sibling tags - head and body. Hence, the <body> tag has only one previous sibling i.e. head, as the following code shows −
html = '''
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Excellent</p><p>Python</p><p>Tutorial</p>
</body>
</head>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.body.previous_siblings
print ("previous siblings:")
for tag in tags:
print (tag)
Output
previous siblings: <head> <title>Hello</title> </head>
Beautiful Soup - next_element Property
Description
In Beautiful Soup library, the next_element property returns the Tag or NavigableString that appears immediately next to the current PageElement, even if it is out of the parent tree. There is also a next property which has similar behaviour
Syntax
Element.next_element
Return value
The next_element and next properties return a tag or a NavigableString appearing immediately next to the current tag.
Example - Usage of next_element property
In the document tree parsed from the given HTML string, we find the next_element of the <b> tag
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.b
print (tag)
nxt = tag.next_element
print ("Next:",nxt)
nxt = tag.next_element.next_element
print ("Next:",nxt)
Output
<b>Excellent</b> Next: Excellent Next: <p>Python</p>
The output is a little strange as the next element for <b>Excellent</b> is shown to be 'Excellent', that is because the inner string is registered as the next element. To obtain the desired result (<p>Python</p>) as the next element, fetch the next_element property of the inner NavigableString object.
Example - Using next property
The BeautifulSoup PageElements also support next property which is analogous to next_element property
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.b
print (tag)
nxt = tag.next
print ("Next:",nxt)
nxt = tag.next.next
print ("Next:",nxt)
Output
<b>Excellent</b> Next: Excellent Next: <p>Python</p>
Example - Getting next Element to Body Tag
In the next example, we try to determine the element next to <body> tag. As it is followed by a line break (\n), we need to find the next element of the one next to body tag. It happens to be <h1> tag.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('body')
nxt = tag.next_element.next
print ("Next:",nxt)
Output
Next: <h1>TutorialsPoint</h1>
Beautiful Soup - previous_element Property
Description
In Beautiful Soup library, the previous_element property returns the Tag or NavigableString that appears immediately prior to the current PageElement, even if it is out of the parent tree. There is also a previous property which has similar behaviour
Syntax
Element.previous_element
Return value
The previous_element and previous properties return a tag or a NavigableString appearing immediately before the current tag.
Example - Usage of previous_element Property
In the document tree parsed from the given HTML string, we find the previous_element of the <p id='id1'> tag
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.find('p', id='id1')
print (tag)
pre = tag.previous_element
print ("Previous:",pre)
pre = tag.previous_element.previous_element
print ("Previous:",pre)
Output
<p id="id1">Tutorial</p> Previous: Python Previous: <p>Python</p>
The output is a little strange as the previous element for shown to be 'Python, that is because the inner string is registered as the previous element. To obtain the desired result (<p>Python</p>) as the previous element, fetch the previous_element property of the inner NavigableString object.
Example - Using previous Property
The BeautifulSoup PageElements also supports previous property which is analogous to previous_element property
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.find('p', id='id1')
print (tag)
pre = tag.previous
print ("Previous:",pre)
pre = tag.previous.previous
print ("Previous:",pre)
Output
<p id="id1">Tutorial</p> Previous: Python Previous: <p>Python</p>
Example - Using previous_element property for input tags
In the next example, we try to determine the element next to <input> tag whose id attribute is 'age'
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html5lib')
tag = soup.find('input', id='age')
pre = tag.previous_element.previous
print ("Previous:",pre)
Output
Previous: <input id="nm" name="name" type="text"/>
Beautiful Soup - next_elements Property
Description
In Beautiful Soup library, the next_elements property returns a generator object containing the next strings or tags in the parse tree.
Syntax
Element.next_elements
Return value
The next_elements property returns a generator.
Example - Usage of next_elements property
The next_elements property returns tags and NavibaleStrings appearing after the <b> tag in the document string below −
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('b')
nexts = tag.next_elements
print ("Next elements:")
for next in nexts:
print (next)
Output
Next elements: ExcellentPython
Python <p id="id1">Tutorial</p> Tutorial
Example - Fetching all elements after a Tag
All the elements appearing after the <p> tag are listed below −
from bs4 import BeautifulSoup
html = '''
<p>
<b>Excellent</b><i>Python</i>
</p>
<u>Tutorial</u>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.find('p')
print ("Next elements:")
print (list(tag1.next_elements))
Output
Next elements: ['\n', <b>Excellent</b>, 'Excellent', <i>Python</i>, 'Python', '\n', '\n', <u>Tutorial</u>, 'Tutorial', '\n']
Example - Fetching elements after input Tag
The elements next to the input tag present in the HTML form of index.html are listed below −
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html5lib')
tag = soup.find('input')
nexts = tag.next_elements
print ("Next elements:")
for next in nexts:
print (next)
Output
Next elements: <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/>
Beautiful Soup - previous_elements Property
Description
In Beautiful Soup library, the previous_elements property returns a generator object containing the previous strings or tags in the parse tree.
Syntax
Element.previous_elements
Return value
The previous_elements property returns a generator.
Example - Usage of previous_elements Property
The previous_elements property returns tags and NavibaleStrings appearing before the <p> tag in the document string below −
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', id='id1')
pres = tag.previous_elements
print ("Previous elements:")
for pre in pres:
print (pre)
Output
Previous elements: Python <p>Python</p> Excellent <b>Excellent</b> <p><b>Excellent</b><p>Python</p><p id="id1">Tutorial</p></p>
Example - Getting Elements before a Tag
All the elements appearing before the <u> tag are listed below −
from bs4 import BeautifulSoup
html = '''
<p>
<b>Excellent</b><i>Python</i>
</p>
<u>Tutorial</u>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.find('u')
print ("previous elements:")
print (list(tag1.previous_elements))
Output
previous elements: ['\n', '\n', 'Python', <i>Python</i>, 'Excellent', <b>Excellent</b>, '\n', <p> <b>Excellent</b><i>Python</i> </p>, '\n']
Example - Checking Previous Elements of soup object
The BeautifulSoup object itself doesn't have any previous elements −
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html5lib')
tag = soup.find('input', id='marks')
pres = soup.previous_elements
print ("Previous elements:")
for pre in pres:
print (pre.name)
Output
Previous elements:
Beautiful Soup - find() Method
Method Description
The find() method in Beautiful Soup looks for the first Element that matches the given criteria in the children of this PageElement and returns it.
Syntax
Soup.find(name, attrs, recursive, string, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
recursive − If this is True, find() a recursive search will be performed. Otherwise, only the direct children will be considered.
limit − Stop looking after specified number of occurrences have been found.
kwargs − A dictionary of filters on attribute values.
Return value
The find() method returns Tag object or a NavigableString object
Example - Finding an Element by an ID
The following Python code finds the element with its id as nm
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find(id = 'nm')
print (obj)
Output
<input id="nm" name="name" type="text"/>
Example - Finding First Tag matching given attribute
The find() method returns the first tag in the parsed document that has the given attributes.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find(attrs={"name":'marks'})
print (obj)
Output
<input id="marks" name="marks" type="text"/>
Example - Case of no match
If find() can't find anything, it returns None
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find('dummy')
print (obj)
Output
None
Beautiful Soup - find_all() Method
Method Description
The find_all() method in Beautiful Soup looks for the elements that match the given criteria in the children of this PageElement and returns a list of all elements.
Syntax
Soup.find_all(name, attrs, recursive, string, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
recursive − If this is True, find() a recursive search will be performed. Otherwise, only the direct children will be considered.
limit − Stop looking after specified number of occurrences have been found.
kwargs − A dictionary of filters on attribute values.
Return type
The find_all() method returns a ResultSet object which is a list generator.
Example - finding all input tags
When we can pass in a value for name, Beautiful Soup only considers tags with certain names. Text strings will be ignored, as will tags whose names that don't match. In this example we pass title to find_all() method.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all('input')
print (obj)
Output
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
Example - finding matching tags using a filtering function
We can pass a string to the name argument of find_all() method. With string you can search for strings instead of tags. You can pass in a string, a regular expression, a list, a function, or the value True.
In this example, a function is passed to name argument. All the name starting with 'A' are returned by find_all() method.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
def startingwith(ch):
return ch.startswith('A')
lst=soup.find_all(string=startingwith)
print (lst)
Output
['Accounts', 'Anand', 'Ankita']
Example - Finding first two appearances of a tag
In this example, we pass limit=2 argument to find_all() method. The method returns first two appearances of <li> tag.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all('li', limit =2)
print (lst)
Output
[<li>Accounts</li>, <li>Anand</li>]
Beautiful Soup - find_parents() Method
Method Description
The find_parent() method in BeautifulSoup package finds all parents of this Element that matches the given criteria.
Syntax
find_parents( name, attrs, limit, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
limit − Stop looking after specified number of occurrences have been found.
kwargs − A dictionary of filters on attribute values.
Return Type
The find_parents() method returns a ResultSet consisting of all the parent elements in a reverse order.
Example - Usage of find parents
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('li')
parents=obj.find_parents()
for parent in parents:
print (parent.name)
Output
ul body html [document]
Note that the name property of BeautifulSoup object always returns [document].
Example - Limiting parents search
In this example, the limit argument is passed to find_parents() method to restrict the parent search to two levels up.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('li')
parents=obj.find_parents(limit=2)
for parent in parents:
print (parent.name)
Output
ul body
Beautiful Soup - find_parent() Method
Method Description
The find_parent() method in BeautifulSoup package finds the closest parent of this PageElement that matches the given criteria.
Syntax
find_parent( name, attrs, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
kwargs − A dictionary of filters on attribute values.
Return Type
The find_parent() method returns Tag object or a NavigableString object.
Example - Usage of find_parent() method
In the following example, we find the name of the tag that is parent to the string 'HR'.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find(string='HR')
print (obj.find_parent().name)
Output
li
Example - Checking parent of body tag
The <body> tag is always enclosed within the top level <html> tag. In the following example, we confirm this fact with find_parent() method −
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('body')
print (obj.find_parent().name)
Output
html
Beautiful Soup - find_next_siblings() Method
Method Description
The find_next_siblings() method is similar to next_sibling property. It finds all siblings at the same level of this PageElement that match the given criteria and appear later in the document.
Syntax
find_fnext_siblings(name, attrs, string, limit, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − The string to search for (rather than tag).
limit − Stop looking after specified number of occurrences have been found.
kwargs − A dictionary of filters on attribute values.
Return Type
The find_next_siblings() method returns a list of Tag objects or a NavigableString objects.
Example - Fetching all Siblings of a Tag
In the code below, we try to find all the siblings of <b> tag. There are two more tags at the same level in the HTML string used for scraping.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('b')
print ("next siblings:")
for tag in tag1.find_next_siblings():
print (tag)
Output
The ResultSet of find_next_siblings() is being iterated with the help of for loop.
next siblings: <i>Python</i> <u>Tutorial</u>
Example - Case of No Siblings
If there are no siblings to be found after a tag, this method returns an empty list.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('u')
print ("next siblings:")
print (tag1.find_next_siblings())
Output
next siblings: []
Beautiful Soup - find_next_sibling() Method
Method Description
The find_next_sibling() method in Beautiful Soup Find the closest sibling at the same level to this PageElement that matches the given criteria and appears later in the document. This method is similar to next_sibling property.
Syntax
find_fnext_sibling(name, attrs, string, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − The string to search for (rather than tag).
kwargs − A dictionary of filters on attribute values.
Return Type
The find_next_sibling() method returns Tag object or a NavigableString object.
Example - Usage of find_next_sibling() method
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.find('b')
print ("next:",tag1.find_next_sibling())
Output
next: <i>Python</i>
Example - Case of no Next Sibling
If the next node doesn't exist, the method returns None.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.find('i')
print ("next:",tag1.find_next_sibling())
Output
next: None
Beautiful Soup - find_previous_siblings() Method
Method Description
The find_previous_siblings() method in Beautiful Soup package returns all siblings that appear earlier to this PageElement in the document and match the given criteria.
Syntax
find_previous_siblings(name, attrs, string, limit, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − A filter for a NavigableString with specific text.
limit − Stop looking after finding this many results.
kwargs − A dictionary of filters on attribute values.
Return Value
The find_previous_siblings() method a ResultSet of PageElements.
Example - Usage of find_previous_siblings() method
In the code below, we try to find all the siblings of <> tag. There are two more tags at the same level in the HTML string used for scraping.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('u')
print ("previous siblings:")
for tag in tag1.find_previous_siblings():
print (tag)
Output
<i>Python</i> <b>Excellent</b>
Example - Find Previous Siblings for input tags
The html content has a HTML form with three input elements. We locate one with id attribute as marks and then find its previous siblings.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sibs = tag.find_previous_siblings()
print (sibs)
Output
[<input id="age" name="age" type="text"/>, <input id="nm" name="name" type="text"/>]
Example - Finding Previous Siblings of a tag
The HTML string has two <p> tags. We find out the siblings previous to the one with id1 as its id attribute.
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', id='id1')
ptags = tag.find_previous_siblings()
for ptag in ptags:
print ("Tag: {}, Text: {}".format(ptag.name, ptag.text))
Output
Tag: p, Text: Python Tag: b, Text: Excellent
Beautiful Soup - find_previous_sibling() Method
Method Description
The find_previous_sibling() method in Beautiful Soup returns the closest sibling to this PageElement that matches the given criteria and appears earlier in the document.
Syntax
find_previous_sibling(name, attrs, string, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − A filter for a NavigableString with specific text.
kwargs − A dictionary of filters on attribute values.
Return Value
The find_previous_sibling() method returns a PageElement that could be a Tag or a NavigableString.
Example - Usage of find_previous_sibling() method
From the HTML string used in the following example, we find out the previous sibling of <i> tag, having the tag name as 'u'
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><u>Excellent</u><b>Hello</b><i>Python</i></p>", 'html.parser')
tag = soup.i
sibling = tag.find_previous_sibling('u')
print (sibling)
Output
<u>Excellent</u>
Example - Finding previous sibling of input tag
The html content has a HTML form with three input elements. We locate one with id attribute as marks and then find its previous sibling that had id set to nm.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sib = tag.find_previous_sibling(id='nm')
print (sib)
Output
<input id="nm" name="name" type="text"/>
Example - Checking previous sibling of p tag
In the code below, the HTML string has two <p> elements and a string inside the outer <p> tag. We use find_previous_string() method to search for the NavigableString object sibling of <p>Tutorial</p> tag.
html = '''
<p>Excellent<p>Python</p><p>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string='Tutorial')
ptag = tag.find_previous_sibling(string='Excellent')
print (ptag, type(ptag))
Output
Excellent <class 'bs4.element.NavigableString'>
Beautiful Soup - find_all_next() Method
Method Description
The find_all_next() method in Beautiful Soup finds all PageElements that match the given criteria and appear after this element in the document. This method returns tags or NavigableString objects and method takes in the exact same parameters as find_all().
Syntax
find_all_next(name, attrs, string, limit, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
recursive − If this is True, find() a recursive search will be performed. Otherwise, only the direct children will be considered.
limit − Stop looking after specified number of occurrences have been found.
kwargs − A dictionary of filters on attribute values.
Return Value
This method returns a ResultSet containing PageElements (Tags or NavigableString objects).
Example - Getting all elements after Form Tag
In this example, we first locate the <form> tag and collect all the elements after it with find_all_next() method.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.form
tags = tag.find_all_next()
print (tags)
Output
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
Example - Finding all next elements with filter
Here, we apply a filter to the find_all_next() method to collect all the tags subsequent to <form>, with id being nm or age.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.form
tags = tag.find_all_next(id=['nm', 'age'])
print (tags)
Output
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>]
Example - Finding all elements
If we check the tags following the body tag, it includes a <h1> tag as well as <form> tag, that includes three input elements.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.body
tags = tag.find_all_next()
print (tags)
Output
[<h1>TutorialsPoint</h1> <form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/> </form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/>]
Beautiful Soup - find_next() Method
Method Description
The find_next() method in Beautiful soup finds the first PageElement that matches the given criteria and appears later in the document. returns the first tag or NavigableString that comes after the current tag in the document. Like all other find methods, this method has the following syntax −
Syntax
find_next(name, attrs, string, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − A filter for a NavigableString with specific text.
kwargs − A dictionary of filters on attribute values.
Return Value
This find_next () method returns a Tag or a NavigableString
Example - Finding next element to Form Tag
We first locate the <form> tag and then the one next to it.
from bs4 import BeautifulSoup html = """ <html> <head> <title>TutorialsPoint</title> </head> <body> <h1>TutorialsPoint</h1> <form> <input type = 'text' id = 'nm' name = 'name'> <input type = 'text' id = 'age' name = 'age'> <input type = 'text' id = 'marks' name = 'marks'> </form> </body> </html> """ soup = BeautifulSoup(html, 'html.parser') tag = soup.h1 print (tag.find_next())Output
<form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/> </form>
Example - Finding Next element of Input with filter
In this example, we first locate the <input> tag with its name='age' and obtain its next tag.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_next())
Output
<input id="marks" name="marks" type="text"/>
Example - Finding Tag next ot Head Tag
The tag next to the <head> tag happens to be <title> tag.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.head
print (tag.find_next())
Output
<title>TutorialsPoint</title>
Beautiful Soup - find_all_previous() Method
Method Description
The find_all_previous() method in Beautiful Soup look backwards in the document from this PageElement and finds all the PageElements that match the given criteria and appear before the current element. It returns a ResultsSet of PageElements that comes before the current tag in the document. Like all other find methods, this method has the following syntax −
Syntax
find_previous(name, attrs, string, limit, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − A filter for a NavigableString with specific text.
limit − Stop looking after finding this many results.
kwargs − A dictionary of filters on attribute values.
Return Value
The find_all_previous() method returns a ResultSet of Tag or NavigableString objects. If the limit parameter is 1, the method is equivalent to find_previous() method.
Example - Getting name of previous tag of first input
In this example, name property of each object that appears before the first input tag is displayed.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input')
for t in tag.find_all_previous():
print (t.name)
Output
form h1 body title head html
Example - Getting previous tags of Input with attributes
In the HTML document under consideration (index.html), there are three input elements. With the following code, we print the tag names of all preceding tags before thr <input> tag with nm attribute as marks. To differentiate between the two input tags before it, we also print the attrs property. Note that the other tags don't have any attributes.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'name':'marks'})
pretags = tag.find_all_previous()
for pretag in pretags:
print (pretag.name, pretag.attrs)
Output
input {'type': 'text', 'id': 'age', 'name': 'age'}
input {'type': 'text', 'id': 'nm', 'name': 'name'}
form {}
h1 {}
body {}
title {}
head {}
html {}
Example - Getting No element
The BeautifulSoup object stores the entire document's tree. It doesn't have any previous element, as the example below shows −
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tags = soup.find_all_previous()
print (tags)
Output
[]
Beautiful Soup - find_previous() Method
Method Description
The find_previous() method in Beautiful Soup look backwards in the document from this PageElement and find the first PageElement that matches the given criteria. It returns the first tag or NavigableString that comes before the current tag in the document. Like all other find methods, this method has the following syntax −
Syntax
find_previous(name, attrs, string, **kwargs)
Parameters
name − A filter on tag name.
attrs − A dictionary of filters on attribute values.
string − A filter for a NavigableString with specific text.
kwargs − A dictionary of filters on attribute values.
Return Value
The find_previous() method returns a Tag or NavigableString object.
Example - Finding previous object of Body Tag
In the example below, we try to find which is the previous object before the <body> tag. It happens to be <title> element.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.body
print (tag.find_previous())
Output
<title>TutorialsPoint</title>
Example - Getting previous element of an input tag
There are three input elements in the HTML document used in this example. The following code locates the input element with name attribute = age and looks for its previous element.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_previous())
Output
<input id="nm" name="name" type="text"/>
Example - Finding previous element of title tag
The element before <title> happens to be <head> element.
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('title')
print (tag.find_previous())
Output
<head> <title>TutorialsPoint</title> </head>
Beautiful Soup - select() Method
Method Description
In Beautiful Soup library, the select() method is an important tool for scraping the HTML/XML document. Similar to find() and find_*() methods, the select() method also helps in locating an element that satisfies a given criteria. The selection of an element in the document tree is done based on the CSS selector given to it as an argument.
Beautiful Soup also has select_one() method. Difference in select() and select_one() is that, select() returns a ResultSet of all the elements belonging to the PageElement and characterized by the CSS selector; whereas select_one() returns the first occurrence of the element satisfying the CSS selector based selection criteria.
Prior to Beautiful Soup version 4.7, the select() method used to be able to support only the common CSS selectors. With version 4.7, Beautiful Soup was integrated with Soup Sieve CSS selector library. As a result, much more selectors can now be used. In the version 4.12, a .css property has been added in addition to the existing convenience methods, select() and select_one().
Syntax
select(selector, limit, **kwargs)
Parameters
selector − A string containing a CSS selector.
limit − After finding this number of results, stop looking.
kwargs − Keyword arguments to be passed.
If the limit parameter is set to 1, it becomes equivalent to select_one() method.
Return Value
The select() method returns a ResultSet of Tag objects. The select_one() method returns a single Tag object.
The Soup Sieve library has different types of CSS selectors. The basic CSS selectors are −
Type selectors match elements by node name. For example −
tags = soup.select('div')
The Universal selector (*) matches elements of any type. Example −
tags = soup.select('*')
The ID selector matches an element based on its id attribute. The symbol # denotes the ID selector. Example −
tags = soup.select("#nm")
The class selector matches an element based on the values contained in the class attribute. The . symbol prefixed to the class name is the CSS class selector. Example −
tags = soup.select(".submenu")
Example: Type Selector
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
Output
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
Example: ID selector
from bs4 import BeautifulSoup
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
'''
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
Output
[<input id="nm" name="name" type="text"/>]
Example: class selector
html = '''
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.select(".mainmenu")
print (tags)
Output
[<li class="mainmenu">Accounts</li>, <li class="mainmenu">HR</li>]
Beautiful Soup - append() Method
Method Description
The append() method in Beautiful Soup adds a given string or another tag at the end of the current Tag object's contents. The append() method works similar to the append() method of Python's list object.
Syntax
append(obj)
Parameters
obj − any PageElement, may be a string, a NavigableString object or a Tag object.
Return Type
The append() method doesn't return a new object.
Example - Appending text to p tag
In the following example, the HTML script has a <p> tag. With append(), additional text is appended. In the following example, the HTML script has a <p> tag. With append(), additional text is appended.
from bs4 import BeautifulSoup
markup = '<p>Hello</p>'
soup = BeautifulSoup(markup, 'html.parser')
print (soup)
tag = soup.p
tag.append(" World")
print (soup)
Output
<p>Hello</p> <p>Hello World</p>
Example - Appending a New Tag to an Existing Tag
With the append() method, you can add a new tag at the end of an existing tag. First create a new Tag object with new_tag() method and then pass it to the append() method.
from bs4 import BeautifulSoup, Tag
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('i')
tag1.string = 'World'
tag.append(tag1)
print (soup.prettify())
Output
<b>
Hello
<i>
World
</i>
</b>
Example - Appending a String to the document
If you have to add a string to the document, you can append a NavigableString object.
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_string = NavigableString(" World")
tag.append(new_string)
print (soup.prettify())
Output
<b> Hello World </b>
Beautiful Soup - extend() Method
Method Description
The extend() method in Beautiful Soup has been added to Tag class from version 4.7 onwards. It adds all the elements in a list to the tag. This method is analogous to a standard Python List's extend() method - it takes in an array of strings to append to the tag's content.
Syntax
extend(tags)
Parameters
tags − A list of srings or NavigableString objects to be appended.
Return Type
The extend() method doesn't return any new object.
Example - Appending a List of strings to a Tag
from bs4 import BeautifulSoup markup = '<b>Hello</b>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b vals = ['World.', 'Welcome to ', 'TutorialsPoint'] tag.extend(vals) print (soup.prettify())
Output
<b> Hello World. Welcome to TutorialsPoint </b>
Beautiful Soup - NavigableString() Method
Method Description
The NavigableString() method in bs4 package is the constructor method for NavigableString class. A NavigableString represents the innermost child element of a parsed document. This method casts a regular Python string to a NavigableString. Conversely, the built-in str() method coverts NavigableString object to a Unicode string.
Syntax
NavigableString(string)
Parameters
string − an object of Python's str class.
Return Value
The NavigableString() method returns a NavigableString object.
Example - Adding a NavigableString
In the code below, the HTML string contains an empty <b> tag. We add a NavigableString object in it.
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello World")
soup.b.append(navstr)
print (soup)
Output
<p><b>Hello World</b></p>
Example - Adding Multiple NavigableString
In this example, we see that two NavigableString objects are appended to an empty <b> tag. The tag responds to strings property instead of string property. It is a generator of NavigableString objects.
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello")
soup.b.append(navstr)
navstr = NavigableString("World")
soup.b.append(navstr)
for s in soup.b.strings:
print (s, type(s))
Output
Hello <class 'bs4.element.NavigableString'> World <class 'bs4.element.NavigableString'>
Example - Accessing stripped_strings property
Instead of strings property, if we access the stripped_strings property of <b> tag object, we get a generator of Unicode strings i.e. str objects.
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello")
soup.b.append(navstr)
navstr = NavigableString("World")
soup.b.append(navstr)
for s in soup.b.stripped_strings:
print (s, type(s))
Output
Hello <class 'str'> World <class 'str'>
Beautiful Soup - new_tag() Method
The new_tag() method in Beautiful Soup library creates a new Tag object, that is associated with an existing BeautifulSoup object. You can use this factory method to append or insert the new tag into the document tree.
Syntax
new_tag(name, namespace, nsprefix, attrs, sourceline, sourcepos, **kwattrs)
Parameters
name − The name of the new Tag.
namespace − The URI of the new Tag's XML namespace, optional.
prefix − The prefix for the new Tag's XML namespace, optional.
attrs − A dictionary of this Tag's attribute values.
sourceline − The line number where this tag was found in its source document.
sourcepos − The character position within `sourceline` where this tag was found.
kwattrs − Keyword arguments for the new Tag's attribute values.
Return Value
This method returns a new Tag object.
Example - Creating new anchor tag
The following example shows the use of new_tag() method. A new tag for <a> element. The tag object is initialized with the href and string attributes and then inserted in the document tree.
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Welcome to <b>online Tutorial library</b></p>', 'html.parser')
tag = soup.new_tag('a')
tag.attrs['href'] = "www.tutorialspoint.com"
tag.string = "Tutorialspoint"
soup.b.insert_before(tag)
print (soup)
Output
<p>Welcome to <a href="www.tutorialspoint.com">Tutorialspoint</a><b>online Tutorial library</b></p>
Example - Creating a new input tag.
In the following example, we have a HTML form with two input elements. We create a new input tag and append it to the form tag.
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
</form>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.form
newtag=soup.new_tag('input', attrs={'type':'text', 'id':'marks', 'name':'marks'})
tag.append(newtag)
print (soup)
Output
<form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/></form>
Example - Inserting a new tag
Here we have an empty <p> tag in the HTML string. A new tag is inserted in it.
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p></p>', 'html.parser')
tag = soup.new_tag('b')
tag.string = "Hello World"
soup.p.insert(0,tag)
print (soup)
Output
<p><b>Hello World</b></p>
Beautiful Soup - insert() Method
Method Description
The insert() method in Beautiful Soup add an element at the given position in a the list of children of a Tag element. The insert() method in Beautiful Soup behaves similar to insert() on a Python list object.
Syntax
insert(position, child)
Parameters
position − The position at which the new PageElement should be inserted.
child − A PageElement to be inserted.
Return Type
The insert() method doesn't return any new object.
Example - Inserting a new String
In the following example, a new string is added to the <b> tag at position 1. The resultant parsed document shows the result.
from bs4 import BeautifulSoup, NavigableString markup = '<b>Excellent </b><u>from TutorialsPoint</u>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b tag.insert(1, "Tutorial ") print (soup.prettify())
Output
<b> Excellent Tutorial </b> <u> from TutorialsPoint </u>
Example - Inserting multiple strings
In the following example, the insert() method is used to successively insert strings from a list to a <p> tag in HTML markup.
from bs4 import BeautifulSoup, NavigableString
markup = '<p>Excellent Tutorials from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
langs = ['Python', 'Java', 'C']
i=0
for lang in langs:
i+=1
tag = soup.new_tag('p')
tag.string = lang
soup.p.insert(i, tag)
print (soup.prettify())
Output
<p>
Excellent Tutorials from TutorialsPoint
<p>
Python
</p>
<p>
Java
</p>
<p>
C
</p>
</p>
Beautiful Soup - insert_before() Method
Method Description
The insert_before() method in Beautiful soup inserts tags or strings immediately before something else in the parse tree. The inserted element becomes the immediate predecessor of this one. The inserted element can be a tag or a string.
Syntax
insert_before(*args)
Parameters
args − One or more elements, may be tag or a string.
Return Value
This insert_before() method doesn't return any new object.
Example - Inserting a Text before a Text
The following example inserts a text "Here is an" before "Excellent in the given HTML markup string.
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent</b> Python Tutorial <u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("Here is an ")
print (soup.prettify())
Output
Here is an <b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
Example - Inserting a Tag before Another Tag
You can also insert a tag before another tag. Take a look at this example.
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorial</b> from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('b')
tag1.string = "Python "
tag.insert_before(tag1)
print (soup.prettify())
Output
<p>
Excellent
<b>
Python
</b>
<b>
Tutorial
</b>
from TutorialsPoint
</p>
Example - Inserting Multiple Strings
The following code passes more than one strings to be inserted before the <b> tag.
from bs4 import BeautifulSoup
markup = '<p>There are <b>Tutorials</b> <u>from TutorialsPoint</u></p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("many ", 'excellent ')
print (soup.prettify())
Output
<p>
There are
many
excellent
<b>
Tutorials
</b>
<u>
from TutorialsPoint
</u>
</p>
Beautiful Soup - insert_after() Method
Method Description
The insert_after() method in Beautiful soup inserts tags or strings immediately after something else in the parse tree. The inserted element becomes the immediate successor of this one. The inserted element can be a tag or a string.
Syntax
insert_after(*args)
Parameters
args − One or more elements, may be tag or a string.
Return Value
This insert_after() method doesn't return any new object.
Example - Inserting a Text after First Tag
Following code inserts a string "Python" after the first <b> tag.
from bs4 import BeautifulSoup
markup = '<p>An <b>Excellent</b> Tutorial <u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_after("Python ")
print (soup.prettify())
Output
<p>
An
<b>
Excellent
</b>
Python
Tutorial
<u>
from TutorialsPoint
</u>
</p>
Example - Inserting a Tag Before another tag
You can also insert a tag before another tag. Take a look at this example.
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorial</b> from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('b')
tag1.string = "on Python "
tag.insert_after(tag1)
print (soup.prettify())
Output
<p>
Excellent
<b>
Tutorial
</b>
<b>
on Python
</b>
from TutorialsPoint
</p>
Example - Inserting multiple String after a tag
Multiple tags or strings can be inserted after a certain tags.
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorials</b> from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
tag1 = soup.new_tag('i')
tag1.string = 'and Java'
tag.insert_after("on Python", tag1)
print (soup.prettify())
Output
<p>
Excellent
<b>
Tutorials
</b>
from TutorialsPoint
</p>
on Python
<i>
and Java
</i>
Beautiful Soup - clear() Method
Method Description
The clear() method in Beautiful Soup library removes the inner content of a tag, keeping the tag intact. If there are any child elements, extract() method is called on them. If decompose argument is set to True, then decompose() method is called instead of extract().
Syntax
clear(decompose=False)
Parameters
decompose − If this is True, decompose() (a more destructive method) will be called instead of extract()
Return Value
The clear() method doesn't return any object.
Example - Clearing entire document
As clear() method is called on the soup object that represents the entire document, all the content is removed, leaving the document blank.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.clear()
print(soup)
Output
Example - Clearing p tags
In the following example, we find all the <p> tags and call clear() method on each of them.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all('p')
for tag in tags:
tag.clear()
print(soup)
Output
Contents of each <p> .. </p> will be removed, the tags will be retained.
<html> <body> <p></p> <p></p> <p></p> <p></p> </body> </html>
Example - Clearing the Tags with decompose argument as true
Here we clear the contents of <body> tags with decompose argument set to Tue.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find('body')
ret = tags.clear(decompose=True)
print(soup)
Output
<html> <body></body> </html>
Beautiful Soup - extract() Method
Method Description
The extract() method in Beautiful Soup library is used to remove a tag or a string from the document tree. The extract() method returns the object that has been removed. It is similar to how a pop() method in Python list works.
Syntax
extract(index)
Parameters
Index − The position of the element to be removed. None by default.
Return Type
The extract() method returns the element that has been removed from the document tree.
Example - Extracting an Element
html = '''
<div>
<p>Hello Python</p>
</div>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tag1 = soup.find("div")
tag2 = tag1.find("p")
ret = tag2.extract()
print ('Extracted:',ret)
print ('original:',soup)
Output
Extracted: <p>Hello Python</p> original: <div> </div>
Example - Extracting all tags
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tags = soup.find_all()
for tag in tags:
obj = tag.extract()
print ("Extracted:",obj)
print (soup)
Output
Extracted: <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> Extracted: <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> Extracted: <p> The quick, brown fox jumps over a lazy dog.</p> Extracted: <p> DJs flock by when MTV ax quiz prog.</p> Extracted: <p> Junk MTV quiz graced by fox whelps.</p> Extracted: <p> Bawds jog, flick quartz, vex nymphs.</p>
Example - Extracting elements with find() method
You can also use extract() method along with find_next(), find_previous() methods and next_element, previous_element properties.
html = '''
<div>
<p><b>Hello</b><b>Python</b></p>
</div>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tag1 = soup.find("b")
ret = tag1.next_element.extract()
print ('Extracted:',ret)
print ('original:',soup)
Output
Extracted: Hello original: <div> <p><b></b><b>Python</b></p> </div>
Beautiful Soup - decompose() Method
Method Description
The decompose() method destroys current element along with its children, thus the element is removed from the tree, wiping it out and everything beneath it. You can check whether an element has been decomposed, by the `decomposed` property. It returns True if destroyed, false otherwise.
Syntax
decompose()
Parameters
No parameters are defined for this method.
Return Type
The method doesn't return any object.
Example - Calling decompose on soup object
When we call descompose() method on the BeautifulSoup object itself, the entire content will be destroyed.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.decompose()
print ("decomposed:",soup.decomposed)
print (soup)
Output
decomposed: True
document: Traceback (most recent call last):
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~
TypeError: can only concatenate str (not "NoneType") to str
Since the soup object is decomposed, it returns True, however, you get TypeError as shown above.
Example - Removing occurences of p tag
The code below makes use of decompose() method to remove all the occurrences of <p> tags in the HTML string used.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
p_all = soup.find_all('p')
[p.decompose() for p in p_all]
print ("document:",soup)
Output
Rest of the HTML document after removing all <p> tags will be printed.
document: <html> <body> </body> </html>
Example - Clearing body
Here, we find the <body> tag from the HTML document tree and decompose the previous element which happens to be the <title> tag. The resultant document tree omits the <title> tag.
html = '''
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
Hello World
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag = soup.body
tag.find_previous().decompose()
print ("document:",soup)
Output
document: <html> <head> </head> <body> Hello World </body> </html>
Beautiful Soup - replace_with() Method
Method Description
Beautiful Soup's replace_with() method replaces a tag or string in an element with the provided tag or string.
Syntax
replace_with(tag/string)
Parameters
The method accepts a tag object or a string as argument.
Return Type
The replace_method doesn't return a new object.
Example - Replacing p tags
In this example, the <p> tag is replaced by <b> with the use of replace_with() method.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
txt = tag1.string
tag2 = soup.new_tag('b')
tag2.string = txt
tag1.replace_with(tag2)
print (soup)
Output
<html> <body> <b>The quick, brown fox jumps over a lazy dog.</b> </body> </html>
Example - Replacing Inner text of a Tag
You can simply replace the inner text of a tag with another string by calling replace_with() method on the tag.string object.
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
tag1.string.replace_with("DJs flock by when MTV ax quiz prog.")
print (soup)
Output
<html> <body> <p>DJs flock by when MTV ax quiz prog.</p> </body> </html>
Example - Replace next tag
The tag object to be used for replacement can be obtained by any of the find() methods. Here, we replace the text of the tag next to <p> tag.
html = '''
<html>
<body>
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
tag1.find_next('b').string.replace_with('black')
print (soup)
Output
<html> <body> <p>The quick, <b>black</b> fox jumps over a lazy dog.</p> </body> </html>
Beautiful Soup - wrap() Method
Method Description
The wrap() method in Beautiful Soup encloses the element inside another element. You can wrap an existing tag element with another, or wrap the tag's string with a tag.
Syntax
wrap(tag)
Parameters
The tag to be wrapped with.
Return Type
The method returns a new wrapper with the given tag.
Example - Creating a new wrapper over a tag
In this example, the <b> tag is wrapped in <div> tag.
html = '''
<html>
<body>
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = soup.new_tag('div')
tag1.wrap(newtag)
print (soup)
Output
<html> <body> <p>The quick, <div><b>brown</b></div> fox jumps over a lazy dog.</p> </body> </html>
Example - Wrapping a String inside a tag
We wrap the string inside the <p> tag with a wrapper tag.
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>tutorialspoint.com</p>", 'html.parser')
soup.p.string.wrap(soup.new_tag("b"))
print (soup)
Output
<p><b>tutorialspoint.com</b></p>
Beautiful Soup - unwrap() Method
Method Description
The unwrap() method is the opposite of wrap() method. It It replaces a tag with whatever's inside that tag. It removes the tag from an element and returns it.
Syntax
unwrap()
Parameters
The method doesn't require any parameter.
Return Type
The unwrap() method returns the tag that has been removed.
Example - Removing a tag from HTML string
In the following example, the <b> tag from the html string is removed.
html = '''
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = tag1.unwrap()
print (soup)
Output
<p>The quick, brown fox jumps over a lazy dog.</p>
Example - Printing returned value of unwrap method
The code below prints the returned value of unwrap() method.
html = '''
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = tag1.unwrap()
print (newtag)
Output
<b></b>
Example - Stripping markup
The unwrap() method is useful for good for stripping out markup, as the following code shows −
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
#print (soup.unwrap())
for tag in soup.find_all():
tag.unwrap()
print (soup)
Output
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - smooth() Method
Method Description
After calling a bunch of methods that modify the parse tree, you may end up with two or more NavigableString objects next to each other. The smooth() method smooths out this element's children by consolidating consecutive strings. This makes pretty-printed output look more natural following a lot of operations that modified the tree.
Syntax
smooth()
Parameters
This method has no parameters.
Return Type
This method returns the given tag after smoothing.
Example - Smoothing a tag
html ='''<html>
<head>
<title>TutorislsPoint/title>
</head>
<body>
Some Text
<div></div>
<p></p>
<div>Some more text</div>
<b></b>
<i></i> # COMMENT
</body>
</html>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.find('body').sm
for item in soup.find_all():
if not item.get_text(strip=True):
p = item.parent
item.replace_with('')
p.smooth()
print (soup.prettify())
Output
<html>
<head>
<title>
TutorislsPoint/title>
</title>
</head>
<body>
Some Text
<div>
Some more text
</div>
# COMMENT
</body>
</html>
Example - Smooting contents of a tag
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello</p>", 'html.parser')
soup.p.append(", World")
soup.smooth()
print (soup.p.contents)
print(soup.p.prettify())
Output
['Hello, World'] <p> Hello, World </p>
Beautiful Soup - prettify() Method
Method Description
To get a nicely formatted Unicode string, use Beautiful Soup's prettify() method. It formats the Beautiful Soup parse tree so that there each tag is on its own separate line with indentation. It allows to you to easily visualize the structure of the Beautiful Soup parse tree.
Syntax
prettify(encoding, formatter)
Parameters
encoding − The eventual encoding of the string. If this is None, a Unicode string will be returned.
A Formatter object, or a string naming one of the standard formatters.
Return Type
The prettify() method returns a Unicode string (if encoding==None) or a bytestring (otherwise).
Example - Prettifying HTML String
Consider the following HTML string.
<p>The quick, <b>brown fox</b> jumps over a lazy dog.</p>
Using the prettify() method we can better understand its structure −
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.prettify())
Output
<html>
<body>
<p>
The quick,
<b>
brown fox
</b>
jumps over a lazy dog.
</p>
</body>
</html>
Example - Prettifying a tag
You can call prettify() on on any of the Tag objects in the document.
print (soup.b.prettify())
Output
<b> brown fox </b>
The prettify() method is for understanding the structure of the document. However, it should not be used to reformat it, as it adds whitespace (in the form of newlines), and changes the meaning of an HTML document.
He prettify() method can optionally be provided formatter argument to specify the formatting to be used.
There are following possible values for the formatter.
formatter="minimal" − This is the default. Strings will only be processed enough to ensure that Beautiful Soup generates valid HTML/XML.
formatter="html" − Beautiful Soup will convert Unicode characters to HTML entities whenever possible.
formatter="html5" − it's similar to formatter="html", but Beautiful Soup will omit the closing slash in HTML void tags like "br".
formatter=None − Beautiful Soup will not modify strings at all on output. This is the fastest option, but it may lead to Beautiful Soup generating invalid HTML/XML.
Example - Usage of Prettify() with formatters
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.prettify(formatter="minimal"))
print ("html: ")
print(soup.prettify(formatter="html"))
print ("None: ")
print(soup.prettify(formatter=None))
Output
minimal: <p> Il a dit < <sacr bleu!=""> > </sacr> </p> html: <p> Il a dit < <sacr bleu!=""> > </sacr> </p> None: <p> Il a dit < <sacr bleu!=""> > </sacr> </p>
Beautiful Soup - encode() Method
Method Description
The encode() method in Beautiful Soup renders a bytestring representation of the given PageElement and its contents.
The prettify() method, which allows to you to easily visualize the structure of the Beautiful Soup parse tree, has the encoding argument. The encode() method plays the same role as the encoding in prettify() method has.
Syntax
encode(encoding, indent_level, formatter, errors)
Parameters
encoding − The destination encoding.
indent_level − Each line of the rendering will be
indented this many levels. Used internally in recursive calls while pretty-printing.
formatter − A Formatter object, or a string naming one of the standard formatters.
errors − An error handling strategy.
Return Value
The encode() method returns a byte string representation of the tag and its contents.
Example - Encoding using UFT-8
The encoding parameter is utf-8 by default. Following code shows the encoded byte string representation of the soup object.
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (soup.encode('utf-8'))
Output
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d'
Example - Encoding using Formatters
The formatter object has the following predefined values −
formatter="minimal" − This is the default. Strings will only be processed enough to ensure that Beautiful Soup generates valid HTML/XML.
formatter="html" − Beautiful Soup will convert Unicode characters to HTML entities whenever possible.
formatter="html5" − it's similar to formatter="html", but Beautiful Soup will omit the closing slash in HTML void tags like "br".
formatter=None − Beautiful Soup will not modify strings at all on output. This is the fastest option, but it may lead to Beautiful Soup generating invalid HTML/XML.
In the following example, different formatter values are used as argument for encode() method.
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.p.encode(formatter="minimal"))
print ("html: ")
print(soup.p.encode(formatter="html"))
print ("None: ")
print(soup.p.encode(formatter=None))
Output
minimal: b'<p>Il a dit <<Sacr\xc3\xa9 bleu!>></p>' html: b'<p>Il a dit <<Sacré bleu!>></p>' None: b'<p>Il a dit <<Sacr\xc3\xa9 bleu!>></p>'
Example - Encoding using Latin-1
The following example uses Latin-1 as the encoding parameter.
markup = '''
<html>
<head>
<meta content="text/html; charset=ISO-Latin-1" http-equiv="Content-type" />
</head>
<body>
<p>Sacr`e bleu!</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, 'lxml')
print(soup.p.encode("latin-1"))
Output
b'<p>Sacr`e bleu!</p>'
Beautiful Soup - decode() Method
Method Description
The decode() method in Beautiful Soup returns a string or Unicode representation of the parse tree as an HTML or XML document. The method decodes the bytes using the codec registered for encoding. Its function is opposite to that of encode() method. You call encode() to get a bytestring, and decode() to get Unicode. Let us study decode() method with some examples.
Syntax
decode(pretty_print, encoding, formatter, errors)
Parameters
pretty_print − If this is True, indentation will be used to make the document more readable.
encoding − The encoding of the final document. If this is None, the document will be a Unicode string.
formatter − A Formatter object, or a string naming one of the standard formatters.
errors − The error handling scheme to use for the handling of decoding errors. Values are 'strict', 'ignore' and 'replace'.
Return Value
The decode() method returns a Unicode String.
Example - Decoding a UTF-8 encoded String
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
enc = soup.encode('utf-8')
print (enc)
dec = enc.decode()
print (dec)
Output
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d' Hello "World!"
Example - Decoding a latin-1 encoded String
markup = '''
<html>
<head>
<meta content="text/html; charset=ISO-Latin-1" http-equiv="Content-type" />
</head>
<body>
<p>Sacr`e bleu!</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, 'lxml')
enc = soup.p.encode("latin-1")
dec = enc.decode("latin-1")
print (dec)
Output
<p>Sacr`e bleu!</p>
Beautiful Soup - get_text() Method
Method Description
The get_text() method returns only the human-readable text from the entire HTML document or a given tag. All the child strings are concatenated by the given separator which is a null string by default.
Syntax
get_text(separator, strip)
Parameters
separator − The child strings will be concatenated using this parameter. By default it is "".
strip − The strings will be stripped before concatenation.
Return Type
The get_text() method returns a string.
Example - Getting Text from html Content
In the example below, the get_text() method gets text from all the HTML tags.
html = ''' <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text() print(text)
Output
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
Example - Using Separator with get_text() method
In the following example, we specify the separator argument of get_text() method as '#'.
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(separator='#') print(text)
Output
#The quick, brown fox jumps over a lazy dog.# #DJs flock by when MTV ax quiz prog.# #Junk MTV quiz graced by fox whelps.# #Bawds jog, flick quartz, vex nymphs.#
Example - Using strip with get_text() method
Let us check the effect of strip parameter when it is set to True. By default it is False.
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(strip=True) print(text)
Output
The quick, brown fox jumps over a lazy dog.DJs flock by when MTV ax quiz prog.Junk MTV quiz graced by fox whelps.Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - diagnose() Method
Method Description
The diagnose() method in Beautiful Soup is a diagnostic suite for isolating common problems. If you're facing difficulty in understanding what Beautiful Soup is doing to a document, pass the document as argument to the diagnose() function. A report showing you how different parsers handle the document, and tell you if you're missing a parser.
Syntax
diagnose(data)
Parameters
data − the document string.
Return Value
The diagnose() method prints the result of parsing the given document according all the available parsers.
Example - Running diagnostics
Let us take this simple document for our exercise −
<h1>Hello World <b>Welcome</b> <P><b>Beautiful Soup</a> <i>Tutorial</i><p>
The following code runs the diagnostics on the above HTML script −
markup = ''' <h1>Hello World <b>Welcome</b> <P><b>Beautiful Soup</a> <i>Tutorial</i><p> ''' from bs4.diagnose import diagnose diagnose(markup)
The diagonose() output starts with a message showing what all parsers are available −
Diagnostic running on Beautiful Soup 4.12.2 Python version 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] Found lxml version 4.9.2.0 Found html5lib version 1.1
If the document to be diagnosed is a perfect HTML document, the result for all parsers is just about similar. However, in our example, there are many errors.
To begin the built-in html.parser is take up. The report will be as follows −
Trying to parse your markup with html.parser
Here's what html.parser did with the markup:
<h1>
Hello World
<b>
Welcome
</b>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
<p>
</p>
</b>
</p>
</h1>
You can see that Python's built-in parser doesn't insert the <html> and <body> tags. The unclosed <h1> tag is provided with matching <h1> at the end.
Both the html5lib and lxml parsers complete the document by wrapping it in <html>, <head> and <body> tags.
Trying to parse your markup with html5lib
Here's what html5lib did with the markup:
<html>
<head>
</head>
<body>
<h1>
Hello World
<b>
Welcome
</b>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
</b>
</p>
<p>
<b>
</b>
</p>
</h1>
</body>
</html>
With lxml parser, note where the closing </h1> is inserted. Also the incomplete <b> tag is rectified, and the dangling </a> is removed.
Trying to parse your markup with lxml
Here's what lxml did with the markup:
<html>
<body>
<h1>
Hello World
<b>
Welcome
</b>
</h1>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
</b>
</p>
<p>
</p>
</body>
</html>
The diagnose() method parses the document as XML document also, which probably is superfluous in our case.
Trying to parse your markup with lxml-xml
Here's what lxml-xml did with the markup:
<?xml version="1.0" encoding="utf-8"?>
<h1>
Hello World
<b>
Welcome
</b>
<P>
<b>
Beautiful Soup
</b>
<i>
Tutorial
</i>
<p/>
</P>
</h1>
Let us give the diagnose() method a XML document instead of HTML document.
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
Now if we run the diagnostics, even if it's a XML, the html parsers are applied.
Trying to parse your markup with html.parser
Warning (from warnings module):
File "C:\Users\mlath\OneDrive\Documents\Feb23 onwards\BeautifulSoup\Lib\site-packages\bs4\builder\__init__.py", line 545
warnings.warn(
XMLParsedAsHTMLWarning: It looks like you're parsing an XML document using an HTML parser. If this really is an HTML document (maybe it's XHTML?), you can ignore or filter this warning. If it's XML, you should know that using an XML parser will be more reliable. To parse this document as XML, make sure you have the lxml package installed, and pass the keyword argument `features="xml"` into the BeautifulSoup constructor.
With html.parser, a warning message is displayed. With html5lib, the fist line which contains XML version information is commented and rest of the document is parsed as if it is a HTML document.
Trying to parse your markup with html5lib
Here's what html5lib did with the markup:
<!--?xml version="1.0" ?-->
<html>
<head>
</head>
<body>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
</body>
</html>
The lxml html parser doesn't insert the comment, but parses it as HTML.
Trying to parse your markup with lxml
Here's what lxml did with the markup:
<?xml version="1.0" ?>
<html>
<body>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
</body>
</html>
The lxml-xml parser parses the document as XML.
Trying to parse your markup with lxml-xml
Here's what lxml-xml did with the markup:
<?xml version="1.0" encoding="utf-8"?>
<?xml version="1.0" ?>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
The diagnostics report may prove to be useful in finding errors in HTML/XML documents.