- Agile Data Science - Home
- Agile Data Science - Introduction
- Methodology Concepts
- Agile Data Science - Process
- Agile Tools & Installation
- Data Processing in Agile
- SQL versus NoSQL
- NoSQL & Dataflow programming
- Collecting & Displaying Records
- Data Visualization
- Data Enrichment
- Working with Reports
- Role of Predictions
- Extracting features with PySpark
- Building a Regression Model
- Deploying a predictive system
- Agile Data Science - SparkML
- Fixing Prediction Problem
- Improving Prediction Performance
- Creating better scene with agile & data science
- Implementation of Agile
Agile Data Science - Data Processing in Agile
In this chapter, we will focus on the difference between structured, semi-structured and unstructured data.
Structured data
Structured data concerns the data stored in SQL format in table with rows and columns. It includes a relational key, which is mapped into pre-designed fields. Structured data is used on a larger scale.
Structured data represents only 5 to 10 percent of all informatics data.
Semi-structured data
Sem-structured data includes data which do not reside in relational database. They include some of organizational properties that make it easier to analyse. It includes the same process to store them in relational database. The examples of semi-structured database are CSV files, XML and JSON documents. NoSQL databases are considered semistructured.
Unstructured data
Unstructured data represents 80 percent of data. It often includes text and multimedia content. The best examples of unstructured data include audio files, presentations and web pages. The examples of machine generated unstructured data are satellite images, scientific data, photographs and video, radar and sonar data.
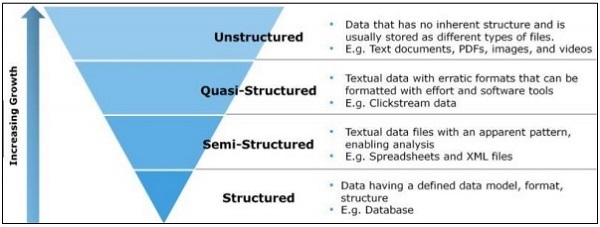
The above pyramid structure specifically focusses on the amount of data and the ratio on which it is scattered.
Quasi-structured data appears as type between unstructured and semi-structured data. In this tutorial, we will focus on semi-structured data, which is beneficial for agile methodology and data science research.
Semi structured data does not have a formal data model but has an apparent, selfdescribing pattern and structure which is developed by its analysis.