
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
What is Overfitting and how to avoid it?
Introduction
In statistics, the phrase "overfitting" is used to describe a modeling error that happens when a function correlates too tightly to a certain set of data. As a result, overfitting could not be able to fit new data, which could reduce the precision of forecasting future observations.
Examining validation measures like accuracy and loss might show overfitting. The validation measures frequently increase until a point at which they level out or start to drop when the model is affected by overfitting. During an upward trend, the model looks for a good match, and once it finds one, the movement starts to turn down or stagnate.
Overfitting is a modeling issue when the model is biased because it is too closely related to the data set.
When a model is overfitting, it is only applicable to the data set that it was designed for and not to any other data sets.
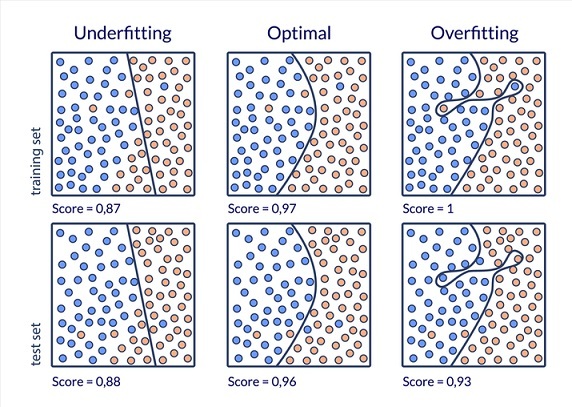
Ensembling, data augmentation, data simplification, and cross-validation are a few techniques used to avoid overfitting.
How to Detect Overfitting?
Before testing the data, it is nearly hard to detect overfitting. It can benefit in addressing overfitting's incapacity to generalize data sets, which is one of its unique features. As a result, it may be possible to split the data up into several subsets to make training and testing easier. A training set and a test set are the two main categories into which the data is split.
About 80% of the total amount of data is represented in the training set, which is also used to train the model. About 20% of the total data set is made up of the test set, which is used to assess the correctness of data that has never been utilized before. We may assess the model's performance on each piece of data to identify overfitting when it occurs and to observe how the training process functions by segmenting the dataset.
The accuracy observed across both data sets might be used to assess performance and establish the presence or absence of overfitting. The model is obviously overfitting if it outperforms the training set and the test set.
How to Prevent Overfitting?
Training with More Data
Using extra data during training is one technique to avoid overfitting. With this setting, algorithms can more easily recognize patterns and reduce errors. The model will become unable to overfit all the samples as the user adds additional training data, forcing it to generalize in order to produce results.
Users should continue to gather more data in order to improve the model's accuracy. Users should make sure that the data being utilized is accurate and relevant because this approach is pricey.
Data Augmentation
Data augmentation, which is less expensive than training with extra data, is an option. If you're unable to keep gathering new data, you might look diversified by using the data sets that are already accessible.
Every time the model processes a sample of data, data augmentation causes a minor change in the sample's appearance. The method stops the model from learning the properties of the data sets while giving each data set the appearance of being unique to the model.
The addition of noise to the input and output data is another technique that functions similarly to data augmentation. While adding noise to the output results in more diverse data, adding noise to the input makes the model more stable without compromising data quality or privacy. However, noise addition should be used sparingly so that the amount of noise does not affect the data's accuracy or consistency too much.
Data Simplification
A model's complex nature can cause overfitting when the model succeeds to overfit the training dataset despite having access to huge amounts of data. The model's complexity is lowered using the data simplification technique, making the model appropriately basic to prevent overfitting.
Pruning a decision tree, lowering the number of parameters in a neural network, and applying dropout on a neutral network are a few examples of the activities that may be put into practice. The model can run more quickly and be lighter if it is simplified.
Ensembling
A machine learning approach called assembling combines predictions from two or more different models. The two most common assembling techniques are bagging and boosting.
Boosting works by employing straightforward base models to raise the total complexity of the models. It instructs plenty of weak learners in sequential order so that each learner in the sequence gains knowledge from the errors of the learner before it.
Boosting brings out one strong learner by combining all the weak learners in the sequence. The alternative to boosting is the ensembling technique known as bagging. In order to maximize predictions, a large number of strong learners are trained in parallel and then combined. This is how bagging works.
Conclusion
Overfitting is the inability of a computer program to generalize data sets. To avoid overfitting, it may be possible to break up the data into training and testing subsets. Users should continue to gather more data in order to improve the model's accuracy. Data augmentation adds noise to the data to give each data set a unique appearance. Noise addition should be used sparingly so that it does not affect the data's accuracy or consistency too much.

644 Views
