
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
What is Load/Store reordering in computer architecture?
Load and store instructions involve actions affecting both the processor and the memory. While executing, both load and stores must first wait for their addresses to be computed by an ALU or address unit. Then, loads can access the data cache to fetch the requested memory data which is then made available in a register. The load is then completed usually by writing the fetched data into the specified architectural register.
Stores have a different execution pattern. After receiving their generated addresses, stores have to wait for their operands to be available. Unlike other instructions, a store is considered to be finished when operands become available. Now let us consider a ROB is in use. When the ROB indicates that the store comes next in sequential execution, the memory address and data to be stored are forwarded to the cache, and a cache store operation is initiated.
A processor that supports weak memory consistency allows the reordering of memory accesses. This is beneficial for at least three methods −
- It allows load/store bypassing.
- It creates speculative loads or stores achievable
- It enables cache misses to be secret
Load/Store bypassing means that either load can bypass pending stores or vice-versa, provided that no memory data dependencies are violated. As shown in the figure, several recent processors allow loads to bypass stores but not vice-versa.
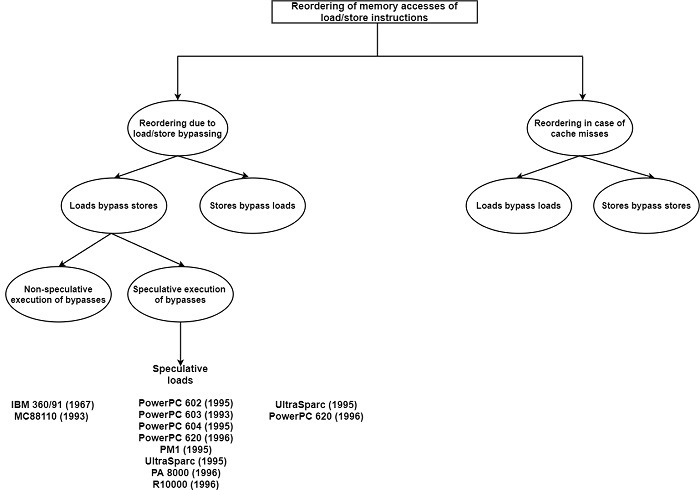
Permitting loads to bypass stores has the advantage of allowing the runtime overlapping of tight loops. The overlapping is achieved by allowing loads at the beginning of an iteration to access memory without having to wait until stores at the end of the previous iterations are completed. It can avoid fetching a false data value, a load can bypass pending stores only if none of the previous stores has the equal target address as the load.
The more advanced handling of this situation is to let loads bypass stores speculatively, that is, to allow speculative loads. Speculative loads avoid delaying memory accesses until all required addresses have been computed and clashing addresses can be ruled out.
The address checks are usually carried out by writing the computing target addresses of loads and stores into the ROB or DRIS and performing the address comparisons here. It can reduce the complexity of the required circuitry, the address check is often restricted to a part of the full effective address.
Cache misses are another source of performance impediment which can be reduced by load/store reordering. A cache miss causes a blockage of all subsequent operations of the same type.

3K+ Views
