
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
Prediction of Wine type using Deep Learning
In recent years, deep learning has gained significant attention for its ability to analyze complex datasets and make accurate predictions, one intriguing application is the prediction of wine types based on various chemical attributes. By leveraging the power of deep learning algorithms, researchers have been able to develop models capable of classifying wines with high accuracy.
This article explores the use of deep learning techniques, such as neural networks, to predict wine types using attributes like alcohol content, acidity, and phenolic compounds. By harnessing the potential of deep learning, wine producers and enthusiasts can enhance their decision-making processes and improve wine quality assessment, ultimately leading to better customer satisfaction and industry advancements.
Prediction of wine type using deep learning
Below are the steps that we will follow to predict the wine type using deep learning ?
Step 1: Importing the required libraries
Pandas is used for data manipulation, NumPy for numerical operations, Matplotlib for data visualization, scikit-learn for data preprocessing, and Keras for building the deep learning model.
Step 2:Load the dataset
It uses the pd.read_csv() function from Pandas to load the dataset into a DataFrame.
Step 3: Data preprocessing
In this step, the features (attributes) are extracted into the variable X, while the target variable (wine type) is extracted into the variable y.
Step 4: Encode the wine types
The wine types are categorical variables, so they need to be encoded as numerical values for the model to understand them. The LabelEncoder() class from scikit-learn is used to convert the wine types into numerical labels.
Step 5: Data analysis
This step provides some basic information about the dataset. It calculates the number of features (attributes), number of classes (unique wine types), and number of samples (rows) in the dataset. It then prints these values for analysis purposes.
Step 6: Split the dataset into training and testing sets
The dataset is split into training and testing sets using the train_test_split() function from scikit-learn. It assigns 80% of the data to the training set and 20% to the testing set. The random_state parameter ensures reproducibility of the results.
Step 7:Standardize the features
Feature scaling is important for deep learning. Here, the StandardScaler() class from scikit-learn is used to standardize the features. The training set is fitted to the scaler using fit_transform(), while the testing set is only transformed using transform() to avoid data leakage.
Step 8: Create the model
This step involves the construction of a deep learning model using the Keras framework. The model follows a sequential structure, where the layers are arranged one after another. The Dense layers signify fully connected layers, where each neuron is connected to every neuron in the previous and subsequent layers.
Example
Below is the program example using the above steps.
import pandas as pdd
import numpy as npp
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as pltt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
# Load the dataset
datasetd = pdd.read_csv('wine.csv')
# Data preprocessing
X = datasetd.iloc[:, 1:].values
y = datasetd.iloc[:, 0].values
# Encode the wine types
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y)
num_features = X.shape[1]
num_classes = len(np.unique(y))
num_samples = X.shape[0]
print(f"Number of samples: {num_samples}")
print(f"Number of features: {num_features}")
print(f"Number of classes: {num_classes}")
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Create the model
model1 = Sequential()
model1.add(Dense(64, activation='relu', input_shape=(num_features,)))
model1.add(Dense(64, activation='relu'))
model1.add(Dense(num_classes, activation='softmax'))
model1.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
history = model1.fit(X_train, y_train, batch_size=32, epochs=50, validation_split=0.2, verbose=1)
# Plot the training history
pltt.plot(history.history['accuracy'])
pltt.plot(history.history['val_accuracy'])
pltt.title('Model Accuracy')
pltt.xlabel('Epoch')
pltt.ylabel('Accuracy')
pltt.legend(['Train', 'Validation'], loc='upper left')
pltt.show()
# Evaluate the model
loss, accuracy = model1.evaluate(X_test, y_test, verbose=0)
print(f'Test Loss: {loss:.4f}')
print(f'Test Accuracy: {accuracy:.4f}')
# Predict on new data
new_data = [[13.24, 2.59, 2.87, 21.0, 118, 2.8, 2.69, 0.39, 1.82, 4.32, 1.04, 2.93, 735]]
new_data_scaled = scaler.transform(new_data)
predictions = model1.predict(new_data_scaled)
predicted_class = npp.argmax(predictions)
# Map predicted class to wine type
predicted_wine_type = label_encoder.inverse_transform([predicted_class])[0]
print(f'Predicted Wine Type: {predicted_wine_type}')
Output
Number of samples: 178 Number of features: 13 Number of classes: 3 Epoch 1/50 4/4 [==============================] - 1s 81ms/step - loss: 1.0252 - accuracy: 0.3805 - val_loss: 0.8866 - val_accuracy: 0.5862 ?????????????????????????????????????????????????????.. Epoch 50/50 4/4 [==============================] - 0s 12ms/step - loss: 0.0109 - accuracy: 1.0000 - val_loss: 0.0520 - val_accuracy: 0.9655
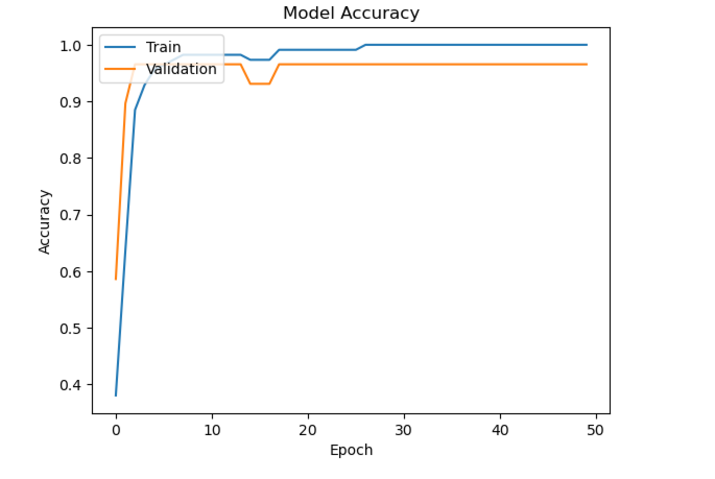
Test Loss: 0.0074 Test Accuracy: 1.0000 1/1 [==============================] - 0s 88ms/step Predicted Wine Type: 1
Conclusion
In summary, the use of deep learning to predict wine types has shown great potential. By harnessing the wealth of data on wine attributes, deep learning algorithms have proven to be successful in precisely categorizing wines based on their chemical composition. This advancement has the power to bring about a significant transformation in the wine industry.
It empowers producers to make well-informed choices regarding grape cultivation, fermentation techniques, and flavor characteristics. Ultimately, this technology holds the key to revolutionizing wine production and refining the decision-making process for producers, leading to improved quality and a more satisfying experience for wine enthusiasts.

358 Views
