- Natural Language Toolkit Tutorial
- Natural Language Toolkit - Home
- Natural Language Toolkit - Introduction
- Natural Language Toolkit - Getting Started
- Natural Language Toolkit - Tokenizing Text
- Training Tokenizer & Filtering Stopwords
- Looking up words in Wordnet
- Stemming & Lemmatization
- Natural Language Toolkit - Word Replacement
- Synonym & Antonym Replacement
- Corpus Readers and Custom Corpora
- Basics of Part-of-Speech (POS) Tagging
- Natural Language Toolkit - Unigram Tagger
- Natural Language Toolkit - Combining Taggers
- Natural Language Toolkit - More NLTK Taggers
- Natural Language Toolkit - Parsing
- Chunking & Information Extraction
- Natural Language Toolkit - Transforming Chunks
- Natural Language Toolkit - Transforming Trees
- Natural Language Toolkit - Text Classification
- Natural Language Toolkit Resources
- Natural Language Toolkit - Quick Guide
- Natural Language Toolkit - Useful Resources
- Natural Language Toolkit - Discussion
More Natural Language Toolkit Taggers
Affix Tagger
One another important class of ContextTagger subclass is AffixTagger. In AffixTagger class, the context is either prefix or suffix of a word. That is the reason AffixTagger class can learn tags based on fixed-length substrings of the beginning or ending of a word.
How does it work?
Its working depends upon the argument named affix_length which specifies the length of the prefix or suffix. The default value is 3. But how it distinguishes whether AffixTagger class learned word’s prefix or suffix?
affix_length=positive − If the value of affix_lenght is positive then it means that the AffixTagger class will learn word’s prefixes.
affix_length=negative − If the value of affix_lenght is negative then it means that the AffixTagger class will learn word’s suffixes.
To make it clearer, in the example below, we will be using AffixTagger class on tagged treebank sentences.
Example
In this example, AffixTagger will learn word’s prefix because we are not specifying any value for affix_length argument. The argument will take default value 3 −
from nltk.tag import AffixTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Prefix_tagger = AffixTagger(train_sentences) test_sentences = treebank.tagged_sents()[1500:] Prefix_tagger.evaluate(test_sentences)
Output
0.2800492099250667
Let us see in the example below what will be the accuracy when we provide value 4 to affix_length argument −
from nltk.tag import AffixTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Prefix_tagger = AffixTagger(train_sentences, affix_length=4 ) test_sentences = treebank.tagged_sents()[1500:] Prefix_tagger.evaluate(test_sentences)
Output
0.18154947354966527
Example
In this example, AffixTagger will learn word’s suffix because we will specify negative value for affix_length argument.
from nltk.tag import AffixTagger from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] Suffix_tagger = AffixTagger(train_sentences, affix_length = -3) test_sentences = treebank.tagged_sents()[1500:] Suffix_tagger.evaluate(test_sentences)
Output
0.2800492099250667
Brill Tagger
Brill Tagger is a transformation-based tagger. NLTK provides BrillTagger class which is the first tagger that is not a subclass of SequentialBackoffTagger. Opposite to it, a series of rules to correct the results of an initial tagger is used by BrillTagger.
How does it work?
To train a BrillTagger class using BrillTaggerTrainer we define the following function −
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) −
templates = [ brill.Template(brill.Pos([-1])), brill.Template(brill.Pos([1])), brill.Template(brill.Pos([-2])), brill.Template(brill.Pos([2])), brill.Template(brill.Pos([-2, -1])), brill.Template(brill.Pos([1, 2])), brill.Template(brill.Pos([-3, -2, -1])), brill.Template(brill.Pos([1, 2, 3])), brill.Template(brill.Pos([-1]), brill.Pos([1])), brill.Template(brill.Word([-1])), brill.Template(brill.Word([1])), brill.Template(brill.Word([-2])), brill.Template(brill.Word([2])), brill.Template(brill.Word([-2, -1])), brill.Template(brill.Word([1, 2])), brill.Template(brill.Word([-3, -2, -1])), brill.Template(brill.Word([1, 2, 3])), brill.Template(brill.Word([-1]), brill.Word([1])), ] trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True) return trainer.train(train_sentences, **kwargs)
As we can see, this function requires initial_tagger and train_sentences. It takes an initial_tagger argument and a list of templates, which implements the BrillTemplate interface. The BrillTemplate interface is found in the nltk.tbl.template module. One of such implementation is brill.Template class.
The main role of transformation-based tagger is to generate transformation rules that correct the initial tagger’s output to be more in-line with the training sentences. Let us see the workflow below −
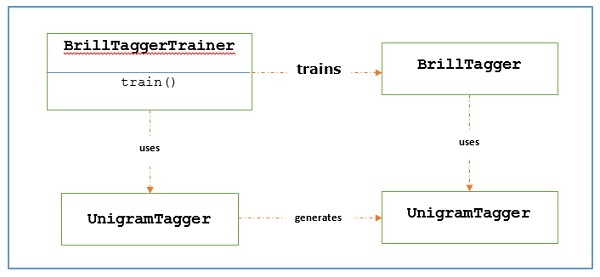
Example
For this example, we will be using combine_tagger which we created while combing taggers (in the previous recipe) from a backoff chain of NgramTagger classes, as initial_tagger. First, let us evaluate the result using Combine.tagger and then use that as initial_tagger to train brill tagger.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
Output
0.9234530029238365
Now, let us see the evaluation result when Combine_tagger is used as initial_tagger to train brill tagger −
from tagger_util import train_brill_tagger brill_tagger = train_brill_tagger(combine_tagger, train_sentences) brill_tagger.evaluate(test_sentences)
Output
0.9246832510505041
We can notice that BrillTagger class has slight increased accuracy over the Combine_tagger.
Complete implementation example
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)
Output
0.9234530029238365 0.9246832510505041
TnT Tagger
TnT Tagger, stands for Trigrams’nTags, is a statistical tagger which is based on second order Markov models.
How does it work?
We can understand the working of TnT tagger with the help of following steps −
First based on training data, TnT tegger maintains several internal FreqDist and ConditionalFreqDist instances.
After that unigrams, bigrams and trigrams will be counted by these frequency distributions.
Now, during tagging, by using frequencies, it will calculate the probabilities of possible tags for each word.
That’s why instead of constructing a backoff chain of NgramTagger, it uses all the ngram models together to choose the best tag for each word. Let us evaluate the accuracy with TnT tagger in the following example −
from nltk.tag import tnt from nltk.corpus import treebank train_sentences = treebank.tagged_sents()[:2500] tnt_tagger = tnt.TnT() tnt_tagger.train(train_sentences) test_sentences = treebank.tagged_sents()[1500:] tnt_tagger.evaluate(test_sentences)
Output
0.9165508316157791
We have a slight less accuracy than we got with Brill Tagger.
Please note that we need to call train() before evaluate() otherwise we will get 0% accuracy.