
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
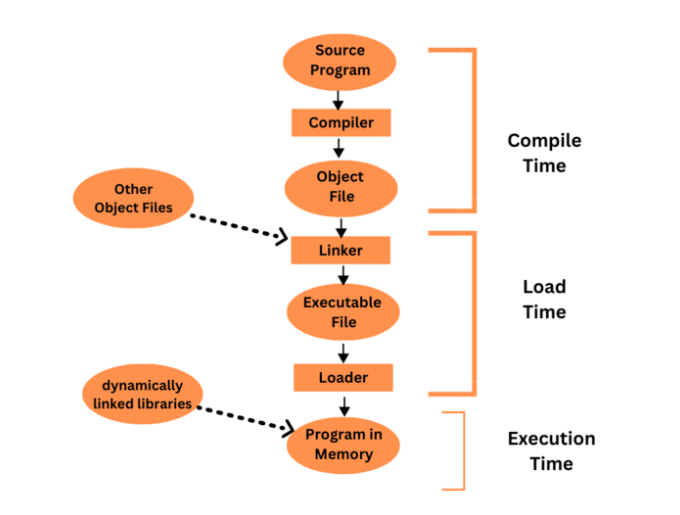
Multistep Processing of a User Program
The computer system must convert a user's high-level programming language program into machine code so that the computer's processor can run it. Multistep processing is the term used to describe the several processes involved in converting a user program into executable code.
A user program will often go through a number of various phases during its multistep processing, including lexical analysis, syntactic analysis, semantic analysis, code creation, optimization, and linking. In order to convert the user program from its high-level form to machine code that can be run on a computer system, each of these stages is essential.
User Program
In contrast to being a component of the operating system or other system software, a user program is a computer program that is written and run by a user. The majority of the time, user programs are created in high-level programming languages and are intended to carry out particular activities like data processing, file management, or user interface interactions.
Text editors, web browsers, music players, and productivity applications like spreadsheet and presentation software are a few examples of user programs. A user normally installs and runs these programs on a computer system to carry out a particular task or set of duties.
A variety of programming languages, including C, C++, Java, Python, or JavaScript, can be used to construct user programs. Depending on the target platform and the programming language, they can either be compiled or interpreted. A user program can be published online for download or distributed to other users after it has been built.
Binding of addresses to memory
The process of mapping logical addresses used by a program to physical addresses in computer memory is known as binding addresses to memory. A computer system has to know where to load program instructions and data into memory, hence this process is crucial to the execution of a program.
There are three kinds of memory binding for addresses?
Compile-time binding ? Binding that is determined at the time of compilation and remains constant throughout the course of the program's execution is known as compile-time binding. These exact addresses are included in the machine code that is generated, and the operating system simply loads that code into memory.
Load-time binding ? In this kind of binding, variables' and instructions' memory addresses are chosen when the program is loading. The operating system loads the code into memory, converts the symbolic references to physical addresses, and then executes the program. The compiler creates relocatable code that contains symbolic references to memory locations.
Run-time binding ? In this kind of binding, variables' and instructions' memory addresses are chosen as they are needed. With this strategy, memory can be allocated dynamically, as needed, while a program is running. This kind of binding is commonly used by programs that make use of dynamic libraries or plug-ins.
Compilation
The conversion of source code written in a high-level programming language into machine language so that it may be executed by a computer is known as compilation. This translation is carried out by a computer program called the compiler. An executable file or object file that may be run on the target system is often the output of a compiler.
Lexical analysis, syntactic analysis, semantic analysis, code creation, and optimization are some of the phases in the compilation process. The following is a succinct description of each of these phases?
Lexical analysis ? This phase entails tokenization of the source code into keywords, identifiers, literals, operators, and so on.
Syntax Analysis ? Analyzing the program's syntax to make sure it complies with the rules of the programming language is the task of the syntax analysis stage. Against the guarantee that the syntax creates a valid program, it is compared to the grammar of the programming language.
Semantic analysis ? This step examines the program's meaning or semantics. It ensures that the program abides by the language's restrictions on variable types, function calls, and other issues.
Code generation ? This step entails turning the source code into machine code or assembly code. The generated code can be immediately executed by the computer's CPU and is typically tailored to the target platform.
Optimization ? During this phase, the code is altered to enhance performance. To cut down on the number of instructions required to run the program, the compiler may use optimization techniques such as loop unrolling, function inlining, and code motion.
Use Cases of Multistep Processing of a User Program
Programming Language Compilation ? The primary use case of multistep processing is the compilation of high-level programming languages into machine code. This enables users to write programs in a human-readable and expressive language and have them translated into executable code that can be run on a computer system.
Error Detection and Debugging ? During the various phases of multistep processing, such as lexical analysis, syntax analysis, and semantic analysis, errors and inconsistencies in the user program are detected. This aids in identifying and debugging issues early in the development process, ensuring the program's correctness and reliability.
Optimization of Program Performance ? The optimization phase in multistep processing focuses on enhancing program performance. Through techniques like code restructuring, loop unrolling, and function inlining, the compiler can generate optimized code that executes more efficiently, resulting in faster and more efficient programs.
Platform-specific Code Generation ? The code generation phase of multistep processing translates the high-level program into machine code or assembly code specific to the target platform. This enables the program to efficiently utilize the resources and features of the underlying hardware architecture, resulting in optimal performance and compatibility.
Integration with External Libraries ? The linking phase in multistep processing involves combining the user program with external libraries or modules. This allows the program to utilize pre-existing functionality and resources, expanding its capabilities without the need to reinvent the wheel. It enables developers to leverage the vast ecosystem of libraries available in the programming language ecosystem.
Example
The below C code demonstrates a simple program that calculates the sum of two integers and prints the result. The variables a and b are initialized with values 5 and 10 respectively, and their sum is stored in the variable sum. The printf function is used to display the sum in the desired format.
#include <stdio.h>
int main() {
int a = 5;
int b = 10;
int sum = a + b;
printf("The sum of %d and %d is %d\n", a, b, sum);
return 0;
}
Output
The output of the program will be:
"The sum of 5 and 10 is 15"
Conclusion
The process of converting a high-level programming language into a computer-executable machine language is known as the multistep processing of a user program. Lexical analysis, syntax analysis, semantic analysis, code generation, optimization, linking, loading, and execution are some of the stages that make up this process. To make sure that the user program is free of errors, optimized, and ready to execute, each stage completes a specified task. An executable file or object file that may be run on the target platform is normally the process output. Understanding the process is critical for software developers in order to produce effective and optimized programs.

828 Views
