- Example - Home
- Example - Environment
- Example - Strings
- Example - Arrays
- Example - Date & Time
- Example - Methods
- Example - Files
- Example - Directories
- Example - Exceptions
- Example - Data Structure
- Example - Collections
- Example - Networking
- Example - Threading
- Example - Applets
- Example - Simple GUI
- Example - JDBC
- Example - Regular Exp
- Example - Apache PDF Box
- Example - Apache POI PPT
- Example - Apache POI Excel
- Example - Apache POI Word
- Example - OpenCV
- Example - Apache Tika
- Example - iText
- Java Useful Resources
- Java - Quick Guide
- Java - Useful Resources
How to extract content from an XML document using Java
Problem Description
How to extract content from an XML document using java.
Solution
Following is the program to extract content from an XML document using java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ExtractContentFromXMLDoc {
public static void main(String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File(
"C:/tika/xmlExample.xml"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Input
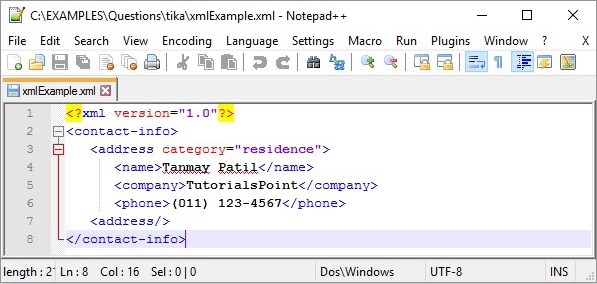
Output
Contents of the document: Tanmay Patil TutorialsPoint (011) 123-4567 Metadata of the document: Content-Encoding: windows-1252 Content-Type: text/html; charset = windows-1252
java_apache_tika
Advertisements