
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
7 Major Challenges Faced By Machine Learning Professionals
This article let us see some of the common challenges Machine Learning Engineers face today.
Introduction
Today when Machine Learning has become the cutting-edge technology in every domain or industry, the number of Machine Learning folks has considerably grown and so is the challenge to implement an Artificial Intelligence project from start to finish, from drafting the concept to bringing the concept to production. The path of a Machine Learning Engineer is not easy as he /she faces numerous challenges along this path.
Collection of Good Quality Data
Yes, this is true. We cannot deny the fact that today data has become the new oil for every industry. Data is gold for them. Data plays a key role in every use case. 60% of the work of a Machine Learning Engineer lies in collecting the data. But the real scenario is a little different from what it seems. Good quality real data are scarce. Most of the data we receive for ML for our industry is maligned with noise and aberrations. This noisy data has to go rigorous cleaning process sometimes consuming around 50% of the whole task. Engineers may sometimes be lucky to get data from well-sourced and developed APIs which can provide useful data but a majority of the time they have to rely on data from scrapers, websites, sensors, etc. which may contain significant noise. The demand for good-quality data is increasing exponentially.
Less Training Data
The data we may be getting from outside sources or in-house data collection methods may be highly deficient or less for the development of a good quality model with decent performance. The scarcity of training data directly hampers a model's performance on newer/unseen data and such a model may not be fit for production.
For example, let's suppose we want to train a Linear Regression model to predict employees' wages in a given organization offered certain parameters. Let's assume that the organization has a very less number of employees (around 50). Here we can say that we will not be able to produce a good model since we don't have many data points from which the model can learn. Here we have a scarcity of data.
Problem of Underfitting
This is a very common problem faced by Machine Learning Engineers. This may also be the direct consequence of less amount of data for training. This can also occur if we have fewer variations in the data. Or if we have removed a significant percentage of data during cleaning and there is not much data left. In underfitting, the mode train even does not perform well on the train set, so it fails to generalize and predict well on unseen data.
For example, in the previous case of the prediction of the wage of employees the engineers using that data may face underfitting problems with the LR model.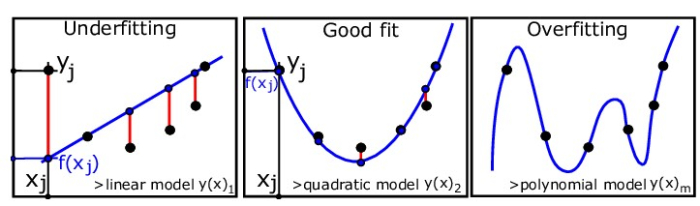
Irrelevant and Unwanted Features.
Many a time the data which ML engineers procure may contain feat a significantly large portion of the dataset that has irrelevant features, an antly large portion of the dataset with irrelevant features then it becomes highly cumbersome to train the model.
For example, in the use case to calculate the wage of a person, the Name of the employee or employee id is irrelevant features since the model(Linear Regression) may not require these features as they are categorical and may not be accepted by a Regression model which mainly takes numerical values.
Problem of Overfitting
Similar to underfitting, there are overfitting issues where the model can produce good results on train data but is not able to generalize well on unseen data or test sets. Hence the model is said to have a lot of high variance error and low bias. A model with high variance may represent the data set accurately but could lead to overfitting to noisy or otherwise unrepresentative training data and the accuracy of the model decreases. Overfitting happens when a model learns that the noise or random fluctuations in the training data set is picked up and learned as concepts by the model.
For example:
Let us suppose we want to model age vs literacy among adults. If we sample a very large part of the population, we will find a clear relationship. This is the signal, whereas noise interferes with the signal. If we do the same for a local population, the relationship will become muddy. It would be affected by outliers and randomness, e.g., one adult went to school early or some adult couldn't afford education, etc.
Model Deployment
Data shows that most of the Machine Learning projects in production fail on first deployments which seem perfectly working on local servers/systems.ML projects require a host of cloud resources like data warehouses, data cleaning pipelines, VMs, Schedulers, etc. Seamless integration of these components is a challenging task for Machine Learning and MLOps Engineers. This task requires a lot of practice and dependencies, a low understanding of underlying models with business, an understanding of business problems, and unstable models.
For example, many cloud services like AWS, Azure, and Google have their own Cloud ML training and deployment pipelines which we can utilize for our use case.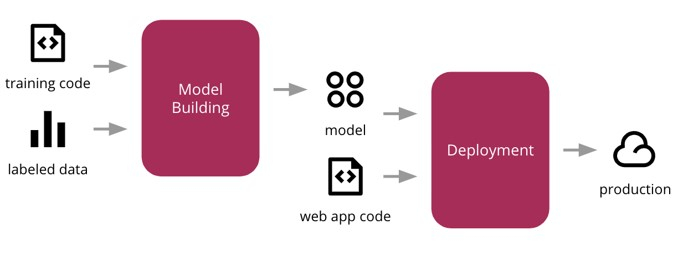
Monitoring and Retraining Approaches.
Monitoring of ML models is a very crucial task and Engineers sometimes find it hard to maintain and keep a watch on model performance and metrics, cause of failure, analysis, etc. Also once trained a model may have to be retrained in the future if the performance degrades or if they receive better quality or newer data.
For example. there are many server-based platforms for monitoring like W&B,Neptune.ai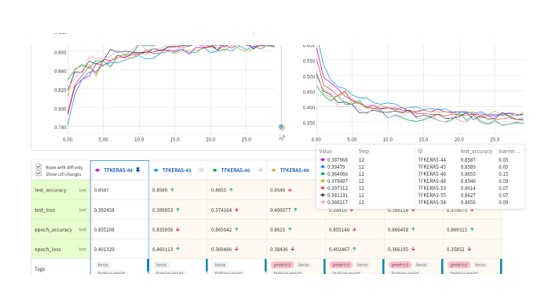
Conclusion
Machine Learning is a complex task and comes with quite a few challenges. It requires skills in many areas such as Data Analysis, proficiency in coding, a good understanding of Machine learning as well as Deployment.

1K+ Views
